


Diseñar alta disponibilidad (HA) para PostgreSQL no va de “poner todo en duplicado” sin más. Se comienza alineando RTO/RPO con la realidad del negocio y evitar complejidad innecesaria. PostgreSQL ofrece varias piezas para hacerlo bien; el reto es elegir y combinarlas de forma inteligente.
¿Qué es HA y cómo medirla?
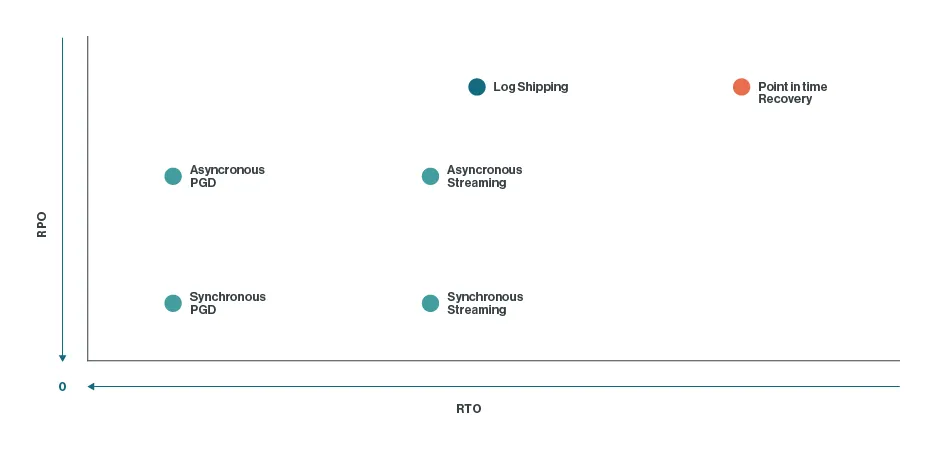
- Recovery Time Objective (RTO): el tiempo máximo aceptable de indisponibilidad hasta volver a operar.
- Recovery Point Objective (RPO): la cantidad máxima de datos que se podrían perder tras un incidente.
Cuanto más te acerques a RTO y RPO cero, mayor será el coste y la complejidad de la solución. El equilibrio es clave.
Términos clave
- Cluster: en HA, es el conjunto de instancias PostgreSQL y componentes auxiliares (gestor de failover, poolers, balanceadores) que actúan como una solución unificada.
- Nodo: servidor físico o virtual donde corre una instancia de PostgreSQL y/o componentes de HA.
- Ubicación: AZ/Región cloud o CPD. Múltiples ubicaciones mejoran la resiliencia ante desastres.
- Witness (árbitro): nodo sin datos que aporta voto de desempate para lograr quórum en promociones automáticas cuando el número de nodos de datos es par.
Preguntas guía para no sobrediseñar
- ¿Replicación física o lógica? ¿Necesitas filtrado, versiones distintas o active-active?
- ¿Failover automatizado (Patroni/EFM/repmgr) o manual con procedimientos claros?
- ¿Una sola AZ con redundancia local, o distribución multi-AZ/multi-región?
- ¿Qué RTO/RPO exige el negocio? ¿Cuál es el presupuesto operativo y de licencias?
- ¿Qué latencia y throughput necesitas en horas pico?
Cómo lograr HA en PostgreSQL
1) PITR (Point-in-Time Recovery)
Recuperar desde backup y reejecutar WAL hasta un punto en el tiempo. Es válido si la ventana de recuperación (RTO) y la pérdida de datos (RPO) resultan aceptables. Depende del tamaño de la base y del volumen de WAL. Útil cuando los cambios son poco frecuentes y se tolera algo de downtime.
2) Replicación: física vs lógica
- Replicación física
- Cómo funciona: transfiere y reproduce los registros WAL completos. Puede ser por log shipping (archivo) o streaming (continuo).
- Ventajas: sencilla, rendimiento alto, replica datos y DDL, bajo overhead en el primario.
- Desventajas: menos flexible (sin filtrado), requiere misma versión mayor, réplicas son read-only.
- Cuándo usarla: HA clásica, DR, réplicas de lectura.
- Replicación lógica (nativa)
- Cómo funciona: captura cambios lógicos (INSERT/UPDATE/DELETE) y los envía como instrucciones.
- Ventajas: flexible (filtrado/transformación), versiones distintas, permite réplicas read-write.
- Desventajas: mayor overhead, posibles conflictos, no replica DDL por defecto, no es práctica para HA robusta nativa.
- Cuándo usarla: analítica, integración de datos, entornos de test/desarrollo, distribución selectiva.
- EDB Postgres Distributed (PGD)
- Qué añade: multi-direccional (active-active), replica DDL, control de consistencia y resolución de conflictos.
- Beneficio: combina la robustez de la física con la flexibilidad de la lógica cuando se requiere escritura en múltiples ubicaciones y cero pérdida.
- Coste/Consideración: mayor complejidad operativa y de diseño; evaluar cuidadosamente si el caso lo justifica.
3) Failover clustering
Para aplicaciones críticas, gestores como EDB Failover Manager (EFM), Patroni o repmgr, combinados con replicación física, automatizan la promoción de réplicas y simplifican el manejo del estado del cluster. PGD incorpora su propio mecanismo de failover.
4) Load balancing
Herramientas como HAProxy reparten conexiones y preservan continuidad durante fallos, sobre todo si cooperan con el gestor de failover para redirigir tráfico al primario vigente.
5) Backups y recuperación
Backups consistentes y verificados con Barman o pgBackRest, más PITR, son indispensables incluso con HA. Copias fuera de la ubicación principal son obligatorias para DR real.
6) Connection Pooling
PgBouncer o Pgpool-II estabilizan el rendimiento bajo picos al reutilizar conexiones y ayudan a redirigir clientes tras un failover, evitando tormentas de conexiones sobre el primario.
Buenas prácticas imprescindibles
- Monitoreo y alertas: visibilidad proactiva con Postgres Enterprise Manager, Prometheus y Grafana. Métricas, logs y salud de réplicas.
- Pruebas periódicas de failover: simula fallos y valida RTO/RPO reales. Ajusta procedimientos.
- Documentación operativa: modos de fallo previstos, runbooks, checklists y responsables. Reduce MTTR.
- Backups y PITR probados: verifica restauraciones y tiempos de recuperación. Ensaya escenarios de corrupción o error humano.
- Gestión de quórum: diseña testigos y reglas de promoción para evitar split-brain.
- Observabilidad de latencia: en diseños multi-AZ/Región, mide impacto de RTT en commit y replicación síncrona.
Patrones de arquitectura de referencia
Cada patrón responde a un nivel de resiliencia, complejidad y coste distinto. Adecúa el tuyo al RTO/RPO del negocio y a las restricciones de latencia.
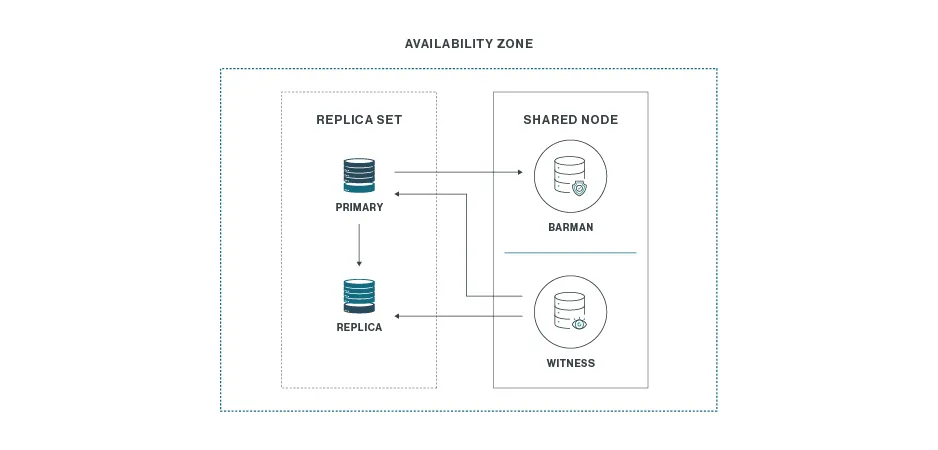
Uno por Tres
Una ubicación, tres nodos.
- Componentes típicos:
- 2 nodos de datos: primario + réplica física en streaming (read-only).
- 1 nodo auxiliar: witness para quórum de promoción y servidor de backup (p. ej., Barman).
- Beneficio: la opción más económica para cubrir la caída de un nodo de datos en la misma ubicación.
- Limitación: no protege ante la pérdida total de la ubicación. Asegura que los backups se almacenen offsite.
- Cuándo elegirlo: si tu riesgo principal es el fallo de un servidor, no un desastre regional, y el RTO/RPO local es suficiente.
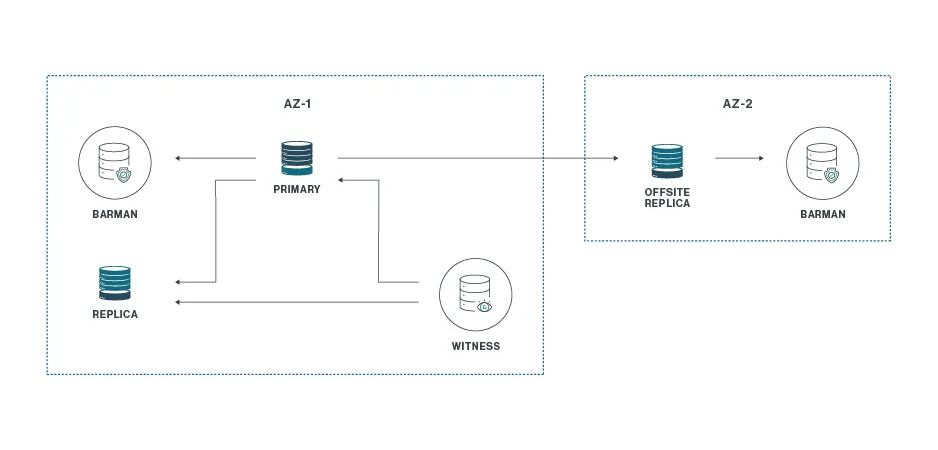
Uno por Tres más Uno
Extiende el patrón anterior añadiendo una ubicación remota para DR.
- Comportamiento: ante la pérdida total del sitio principal, la réplica remota sobrevive, pero sin testigo no hay promoción automática; se requiere intervención manual para promoverla y, si procede, reconstruir el esquema Uno por Tres en el sitio secundario.
- Beneficio: continuidad del servicio ante desastre regional, con coste y complejidad moderados.
- Limitación: sin quórum remoto, el failover es manual; planifica procedimientos y pruebas.
- Cuándo elegirlo: cuando necesitas DR real, aceptas intervención humana y priorizas simplicidad.
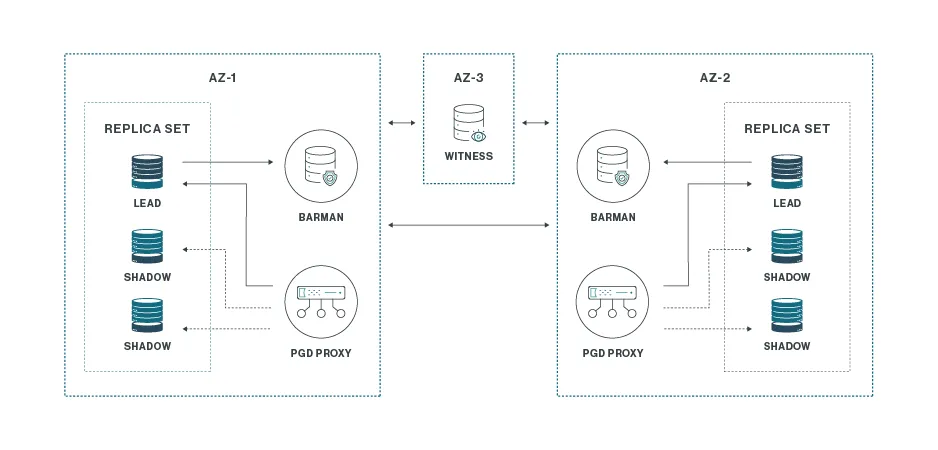
Dos por Tres más Uno
Despliegue avanzado (típicamente con PGD) en dos ubicaciones principales y un testigo en una tercera.
- Componentes:
- Dos ubicaciones activas con tres nodos cada una (resiliencia a fallo de nodo en cada sitio).
- Un nodo witness en una tercera ubicación para asegurar quórum inter-sitios.
- Beneficio: failover transparente y casi instantáneo si se pierde una ubicación completa; protege tanto fallos de nodo como desastres zonales/regionales.
- Coste/Complejidad: mayor footprint, operación y, potencialmente, licencias. Requiere ingeniería cuidadosa de consistencia y conflictos si hay escrituras multi-sitio.
- Cuándo elegirlo: cuando el negocio exige RTO muy bajo y RPO cercano a cero incluso ante la pérdida de una región.
Cómo elegir el patrón correcto
- Define RTO y RPO con el negocio. Sin esto, todo es conjetura.
- Mapea riesgos: fallo de nodo vs. caída de AZ/Región; dependencia de un único storage; errores humanos.
- Mide latencia entre ubicaciones. La replicación síncrona añade RTT al commit.
- Evalúa el coste total: hardware/VMs, licencias, soporte, SRE/operación 24/7.
- Considera madurez operativa: ¿tu equipo puede mantener active-active y resolución de conflictos?
- Ensaya escenarios críticos: corte total del sitio, corrupción, pérdida del primario sin aviso, split-brain.
Conclusión
La alta disponibilidad en PostgreSQL no tiene un único método. Empieza por RTO/RPO, elige la combinación de replicación, failover, backups y balanceo que realmente necesitas, y adopta el patrón de arquitectura que equilibre resiliencia con simplicidad operativa. Con buena observabilidad, pruebas periódicas y documentación clara, tu HA evoluciona sin sobrecargar al equipo.
¿Quieres contrastar tu diseño o necesitas ayuda para ejecutarlo sin sobredimensionar? Hablemos. Contáctanos en hopla.tech/contacto.


