


Standalone Replica Cluster
En este segundo blog, continuación de “CloudNativePG – Replica Cluster – I”, queremos hacer un ejemplo sencillo y práctico de cómo funciona un replica cluster en una configuración denominada: Standalone replica cluster. Si todavía no has leído la primera parte del blog te invitamos a hacerlo aquí: mantente aztualizado con nuestros últimos Insights.
Con este procedimiento queremos mostrar cómo funciona la replicación entre dos clusters diferentes (que pueden estar separados en zonas geográficas distintas) y ver que esta configuración puede ser muy útil para:
- Descargar a nuestro cluster principal de carga analítica.
- Servir como entorno de recuperación ante desastres (DR).
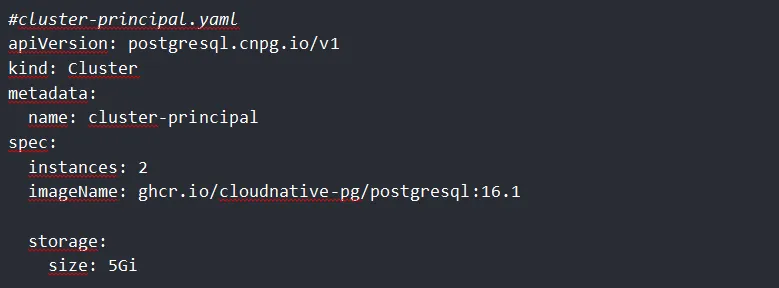
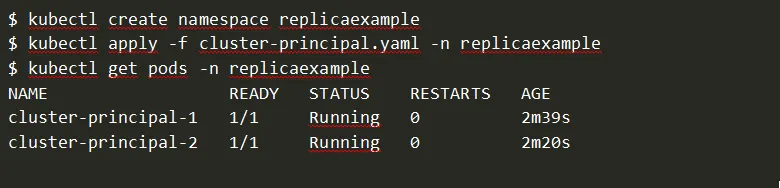
1. Creación del cluster principal
2. Creación del Standalone Replica Cluster
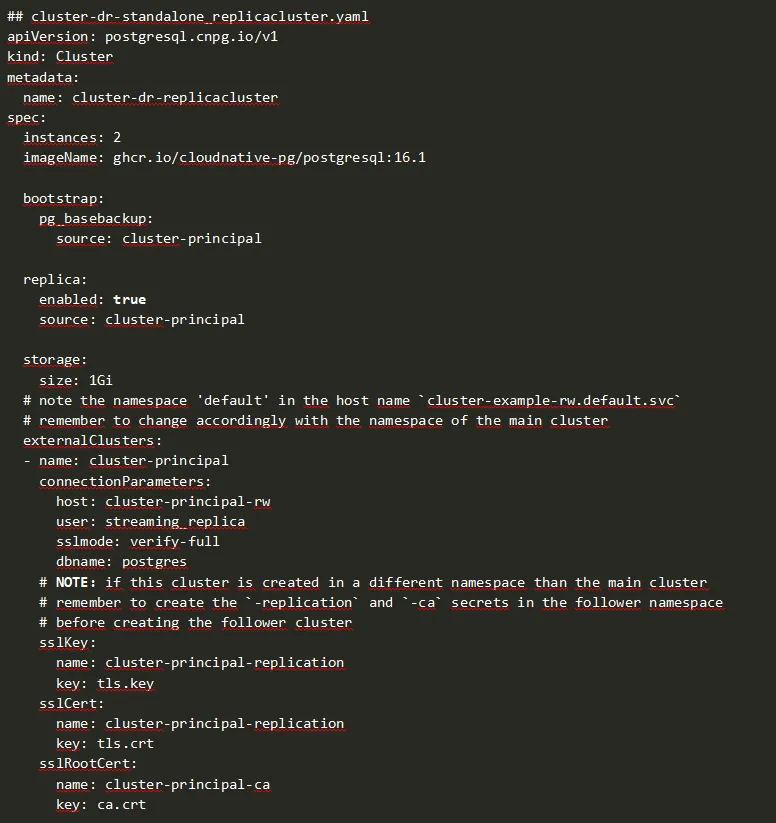
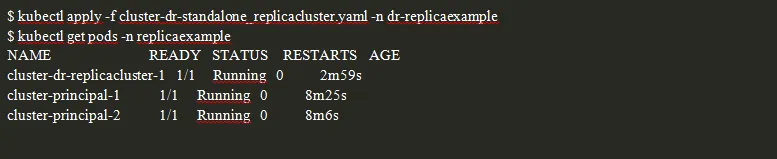
El cluster “cluster-dr-replicacluster” se replica vía streaming replication (para simplificar el ejercicio). Lo habitual es disponer de un almacenamiento S3 o S3 compatible donde configurar el Barman Object Store.

3. Rompemos la réplica y convertimos en dos clusters independientes
Para ello, simplemente se modifica el parámetro [replica.enable] = false
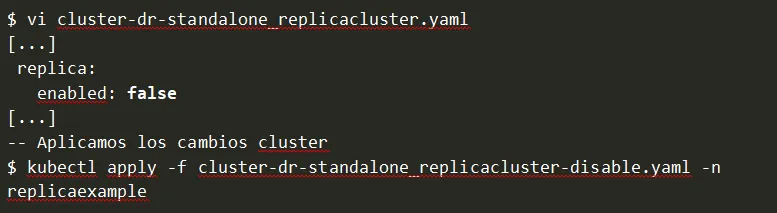
Ahora la replicación ya no funciona y tenemos dos clusters independientes. O visto de otro modo, podemos convertir nuestro cluster de solo lectura en nuestro nuevo cluster de lectura/escritura.
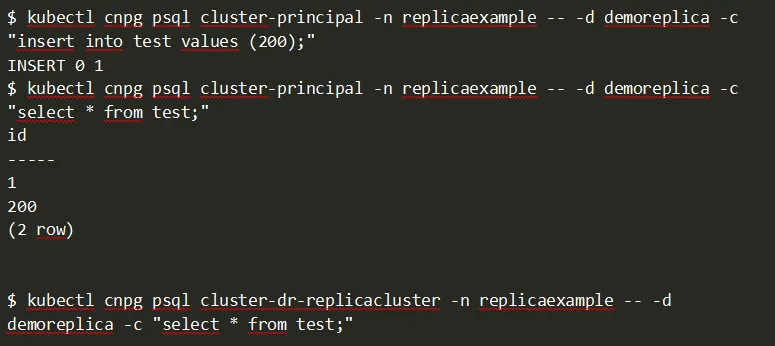

Conclusiones
Este tipo de arquitectura puede ser muy útil si queremos montar una copia de otro entorno, por ejemplo para:
- Descargar a nuestro cluster principal.
- Montar un entorno DR.
- Realizar pruebas en un cluster diferente al de producción.
En el siguiente post, realizaremos una explicación práctica de cómo implementar y configurar una configuración «Distributed Topology«.


