

PostgreSQL Versión 16 – ¿Qué hay de nuevo?
Si no estás familiarizado con PostgreSQL, ¡ nosotros te lo contamos! Es un sistema de gestión de bases de datos relacionales (RDBMS) de código abierto y gratuito que destaca por su enfoque en la extensibilidad y la conformidad con las normativas técnicas. Es ampliamente reconocido por su confiabilidad, rendimiento y capacidad de manejar grandes volúmenes de datos.
Como es habitual de unos años hasta ahora, aproximadamente a finales de septiembre se publica una nueva major release de la base de datos PostgreSQL. Este año acabamos de recibir la última versión de PostgreSQL 16, que nos introduce nuevas características y funcionalidades bastante avanzadas y con mejoras en el rendimiento, gracias, por ejemplo, a los avances introducidos en la ejecución de consultas en paralelo y otras mejoras; como en la carga de grandes volúmenes de datos y la replicación lógica.
Novedades y mejoras en PostgreSQL 16
1. Monitorización
Un aspecto importante para llegar a optimizar el rendimiento de las cargas de trabajo es interpretar y conocer el impacto que tienen las operaciones de E/S en nuestro sistema. Esta versión incluye una nueva vista pg_stat_io , que nos ayuda a identificar patrones de acceso de E/S. Por ejemplo, si observamos altos valores en la columna evictions de la vista, nos podría indicar que debería aumentarse la shared_pool. Recordad que se ha de activar el parámetro track_io_timing para que esta vista pueda recuperar datos.
También es interesante las nuevas columnas last_seq_scan y last_idx_scan en la vista pg_stat_all_tables, que nos proporciona información de la hora en que se realizó el último acceso (scan) de una tabla o un índice.
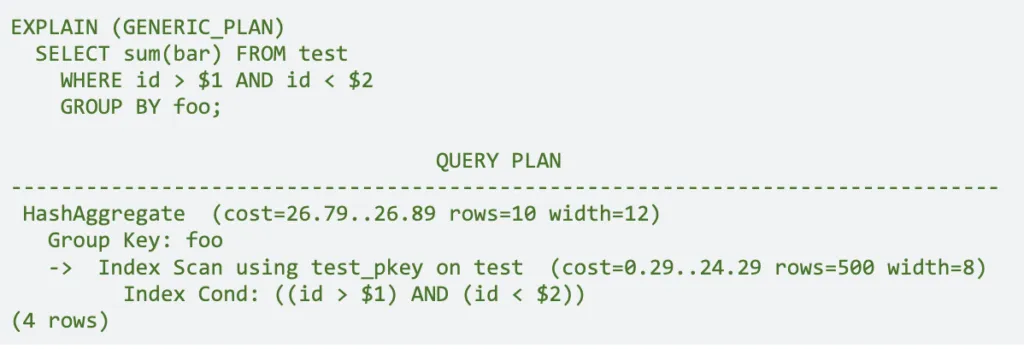
Mejora la legibilidad de auto_explain al registrar los valores utilizados en las consultas parametrizadas. Se ha incorporado un nuevo parámetro GENERIC_PLAN al comando EXPLAIN para ello.
2. Parámetros nuevos en aplicaciones cliente.
-
- Balanceo de conexiones (libpq).
Una interesante funcionalidad añadida a la librería libpq es la de poder especificar múltiples instancias PostgreSQL durante la conexión. Ahora se pueden listar múltiples réplicas bajo los parámetros host, hostaddr y port en la cadena de conexión.
![]()
En el momento de la conexión, los clientes intentarán conectarse a las réplicas en el orden especificado. Sin embargo, para evitar que las aplicaciones intenten conectarse siempre a la primera de las réplicas disponibles, se ha añadido también un nuevo parámetro load_balance_hosts, para elegir uno de los elementos de la lista de manera aleatoria.
![]()
-
- Parámetro watch (psql).
Con este comando se permite repetir una consulta, pero ahora también se permite especificar el número de repeticiones.
![]()
- Parámetro bind (psql).
Mediante el uso de este nuevo comando, ahora se pueden preparar consultas parametrizadas que permite a los usuarios utilizar \bind para sustituir las variables.

3. Rendimiento
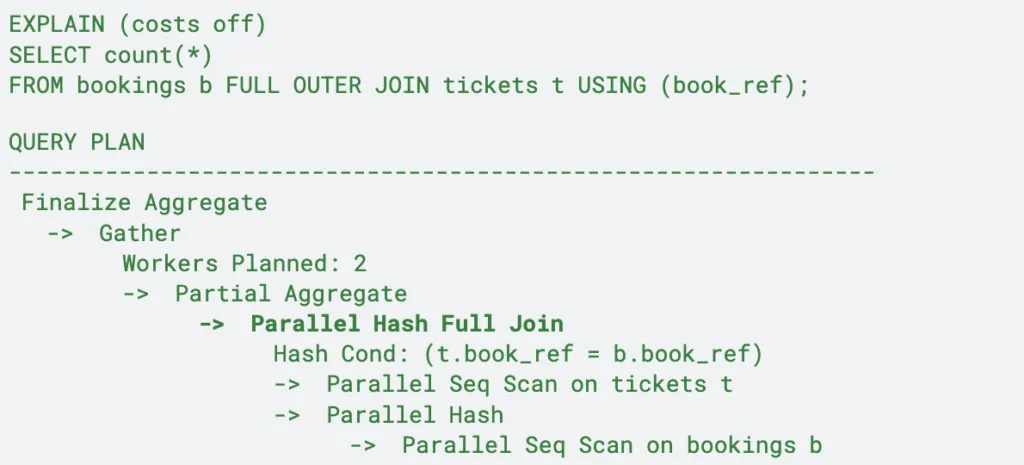
Con esta nueva versión se ha mejorado el optimizador de consultas y ahora se permite la paralelización de uniones hash FULL y right OUTER internas, así como las funciones agregadas string_agg() y array_agg().
Por ejemplo, la siguiente sentencia en versiones anteriores, realizaría un sequential scan, sin embargo ahora en PostgreSQL 16 puede realizarse con parallel
Se introduce también funciones como el almacenamiento en caché de las búsquedas de particiones RANGE y LIST, que ayudan a la carga masiva de datos en tablas particionadas, además de un mejor control del uso del shared_buffer mediante VACUUM y ANALYZE, con la ayuda de un nuevo parámetro (BUFFER_USAGE_LIMIT).
4. Replicación lógica
Mediante la replicación lógica se permite a los usuarios transmitir datos a otras instancias de PostgreSQL o suscriptores que puedan interpretar el protocolo de replicación lógica de PostgreSQL. Esta funcionalidad puede ser útil, por ejemplo, para migraciones de datos o actualizaciones de versiones PostgreSQL .
En esta nueva versión PostgreSQL 16 incluyen una serie de mejoras, las más interesantes son:
- Ahora se permite realizar la replicación lógica a partir de una instancia standby, lo que nos permite publicar los cambios a otros servidores sin tener que usar la base de datos primaria. Esto facilita redistribuir cargas de trabajo entre los diferentes servidores, liberando de carga a nuestra base de datos primaria, que normalmente suele ser muy accedida.
- Los suscriptores pueden realizar operaciones en paralelo en transacciones de gran tamaño y bajo determinadas condiciones, los usuarios tienen la posibilidad de acelerar la sincronización inicial de tablas utilizando el formato binario.

- En el caso de tablas que no cuentan con una clave primaria, los suscriptores pueden emplear índices B-tree en lugar de realizar lecturas secuenciales para localizar registros.
- Para el control de acceso a la replicación lógica, se ha creado un nuevo role pg_create_subscription, lo que permite a los usuarios (que tengan asignado el role y no son superusuarios) la posibilidad de crear nuevas suscripciones lógicas.
- Se añade también soporte para la replicación lógica bidireccional, introduciendo la funcionalidad de replicar datos entre dos tablas de diferentes editores. Aunque tiene ciertas limitaciones como la resolución de conflictos, que tiene que ser gestionado por la propia aplicación o el usuario.
Conclusiones
PostgreSQL 16 ha introducido mejoras en la monitorización del rendimiento, incluyendo vistas que permiten analizar patrones de acceso de E/S y la legibilidad de las consultas parametrizadas.
La replicación lógica ha experimentado mejoras significativas, permitiendo la replicación desde instancias standby y operaciones en paralelo en transacciones de gran tamaño. Asimismo, se ha introducido el soporte para replicación lógica bidireccional, lo que facilita la replicación de datos entre dos tablas de diferentes servidores primarios.
En resumen, PostgreSQL 16 trae consigo una serie de mejoras significativas en términos de rendimiento, monitorización y replicación lógica, lo que lo hace aún más atractivo para aplicaciones que requieren bases de datos relacionales de alto rendimiento y escalabilidad.
Autor del post: Miguel Ángel Prada, Consultor técnico en Hopla! Software.
Si quieres conocer más sobre PostgreSQL o nuestros servicios en Hopla!, echa un vistazo a nuestra web, nuestras redes sociales y canal de YouTube.
Puedes ver todos nuestros webinars sobre PostgreSQL pinchando aquí


