Para empezar, ¿sabías que puedes construir tu propio motor de búsqueda semántica, similar al que utiliza ChatGPT, directamente en tu infraestructura, sin depender de servicios en la nube?
Gracias a Ollama, una herramienta open source que permite ejecutar modelos de lenguaje grandes (LLMs) de forma local, y a PostgreSQL con su extensión pgvector, es posible crear un sistema capaz de comprender el significado del texto, no sólo las palabras.
A continuación te mostraremos cómo integrar Ollama y PostgreSQL para crear una búsqueda inteligente: desde generar embeddings locales, hasta almacenarlos y consultarlos en tu base de datos con pgvector.
De este modo, todo sin enviar tus datos fuera de tu entorno.
Entorno
En particular, para reproducir este ejemplo se utilizó el siguiente entorno:
- Rocky Linux 8
- PostgreSQL 15
- Extensión pgvector
- Ollama 0.12.3 corriendo localmente (ollama server)
- Modelo de embeddings:
ollama pull nomic-embed-text
- Python 3.6.8 con las siguientes librerías:
pip3 install psycopg2-binary requests
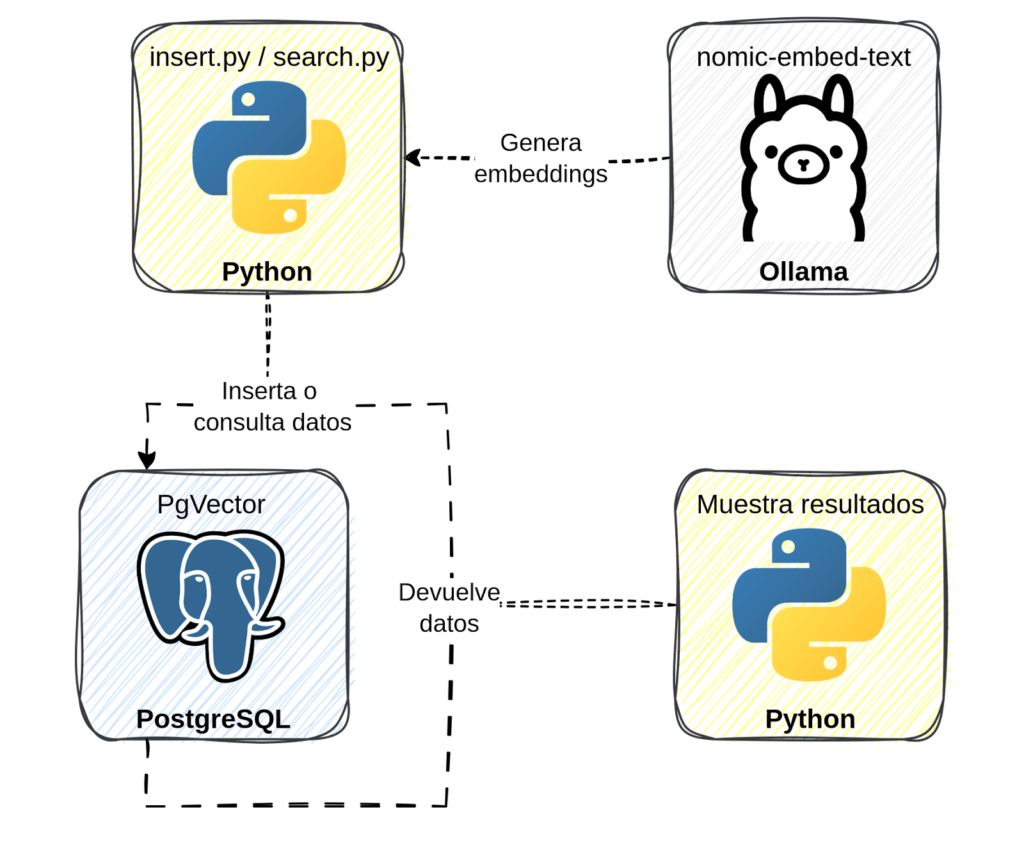
Arquitectura general
| Componente | Función |
| Ollama + nomic-embed-text | Genera embeddings de texto localmente |
| PostgreSQL + pgvector | Almacena y compara embeddings mediante distancia coseno |
| Python | Intermediario entre Ollama y PostgreSQL |
Crear tabla en PostgreSQL
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE docs (
id serial PRIMARY KEY,
content text,
embedding vector(1536)
);
En concreto, el tamaño 1536 en vector(1536) corresponde a la dimensión de embedding generado por el modelo nomic-embed-text de Ollama.
Insertar datos y generar embeddings (insert.py)
En resumen, este script realiza tres tareas principales:
- Comienza por conectarse a PostgreSQL.
- A continuación envía cada texto a Ollama para generar su embedding.
- Para finalizar inserta el texto y su vector en la base de datos.
#!/usr/bin/env python3
import requests
import json
import psycopg2
# Configuración de PostgreSQL
DB_NAME = «postgres»
DB_USER = «postgres»
DB_PASSWORD = «pg123»
DB_HOST = «localhost»
DB_PORT = 5432
# Conexión a PostgreSQL
conn = psycopg2.connect(
dbname=DB_NAME,
user=DB_USER,
password=DB_PASSWORD,
host=DB_HOST,
port=DB_PORT
)
cur = conn.cursor()
# Textos a insertar
texts = [
«PostgreSQL es un motor de base de datos potente y de código abierto.»,
«Python es un lenguaje de programación muy popular.»,
«El cielo es azul debido a la dispersión de Rayleigh.»
]
for text in texts:
# Generar embedding usando Ollama
response = requests.post(
«http://localhost:11434/api/embeddings»,
data=json.dumps({
«model»: «nomic-embed-text»,
«prompt»: text
}),
headers={«Content-Type»: «application/json»}
)
# Validar la respuesta
if response.status_code != 200:
print(«Error al obtener embedding:», response.text)
continue # Saltar este texto y continuar con los demás
embedding = list(map(float, response.json()[«embedding»]))
# Insertar texto y embedding en PostgreSQL
cur.execute(
«INSERT INTO docs (content, embedding) VALUES (%s, %s)»,
(text, embedding)
)
# Confirmar cambios y cerrar conexión
conn.commit()
cur.close()
conn.close()
print(«Embeddings insertados correctamente»)
Búsqueda semántica (search.py)
Del mismo modo este script realiza tres tareas principales:
- Primero se conecta a PostgreSQL.
- Después genera el embedding del texto de búsqueda usando Ollama.
- Para finalizar compara el embedding con los documentos existentes mediante pgvector y devuelve los resultados más similares.
#!/usr/bin/env python3
# Librerías para llamadas HTTP y manejo de JSON
import requests
import json
# Librería para conectarse a PostgreSQL
import psycopg2
# Configuración de PostgreSQL
DB_NAME = «postgres»
DB_USER = «postgres»
DB_PASSWORD = «pg123»
DB_HOST = «localhost»
DB_PORT = 5432
# Conexión a PostgreSQL
conn = psycopg2.connect(
dbname=DB_NAME,
user=DB_USER,
password=DB_PASSWORD,
host=DB_HOST,
port=DB_PORT
)
cur = conn.cursor()
# Texto de búsqueda
query_text = «¿Por qué el cielo es azul?»
# Obtener embedding desde Ollama
response = requests.post(
«http://localhost:11434/api/embeddings»,
headers={«Content-Type»: «application/json»},
data=json.dumps({
«model»: «nomic-embed-text»,
«prompt»: query_text
})
)
# Validar la respuesta
if response.status_code != 200:
print(«Error al obtener embedding:», response.text)
exit(1)
query_embedding = list(map(float, response.json()[«embedding»]))
# Consulta semántica en PostgreSQL
cur.execute(«»»
SELECT content, embedding <=> %s::vector AS similarity
FROM docs
ORDER BY similarity
LIMIT 3
«»», (query_embedding,))
print(«Resultados de búsqueda semántica:\n»)
for content, similarity in cur.fetchall():
print(f»Contenido: {content}\nSimilitud: {similarity}\n»)
cur.close()
conn.close()
Ejemplo de salida
Por ejemplo, resultados de búsqueda semántica:
Contenido: El cielo es azul debido a la dispersión de Rayleigh.
Similitud: 0.22066058643992392
Contenido: Python es un lenguaje de programación muy popular.
Similitud: 0.5083679530423353
Contenido: PostgreSQL es un motor de base de datos potente y de código abierto.
Similitud: 0.543805990239008
Crear un índice para acelerar las búsquedas (opcional)
CREATE INDEX ON docs USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
ANALYZE docs;
Con Python y PostgreSQL, puedes construir tu propio motor de búsqueda semántica completamente local, privado y extensible. PostgreSQL, junto con su extensión pgvector, actúa como el corazón del sistema, almacenando y comparando los embeddings de manera eficiente y confiable. De este modo, este enfoque te permite aprovechar el poder de los modelos de lenguaje modernos sin depender de servicios externos ni exponer tus datos.
Además, la arquitectura es fácilmente ampliable: puedes integrar modelos como Llama3 de Meta AI a través de Ollama, de manera que tu sistema no solo busque información, sino que también genere respuestas contextuales y razonadas en tiempo real, con todo el control y la seguridad que ofrece una base de datos como PostgreSQL.