


La inteligencia artificial es una herramienta eficaz para convertir datos en decisiones y decisiones en resultados de negocio. En una adopción estratégica de la inteligencia artificial, ese potencial se traduce en impacto real para la empresa.
Las empresas que están liderando sus sectores no son necesariamente las que “usan IA”, sino las que entienden cuándo usarla, para qué usarla y cómo llevarla de una idea a producción sin perder control ni confiabilidad.
En Hopla! trabajamos a diario con organizaciones que quieren dar ese paso, pero también necesitan una base sólida. La adopción estratégica de la inteligencia artificial no empieza con la selección de un modelo, sino con una decisión estratégica bien tomada. Por eso conviene recorrer los fundamentos que hacen que un proyecto de inteligencia artificial tenga sentido desde el punto de vista técnico y de negocio.
Qué entendemos hoy por inteligencia artificial
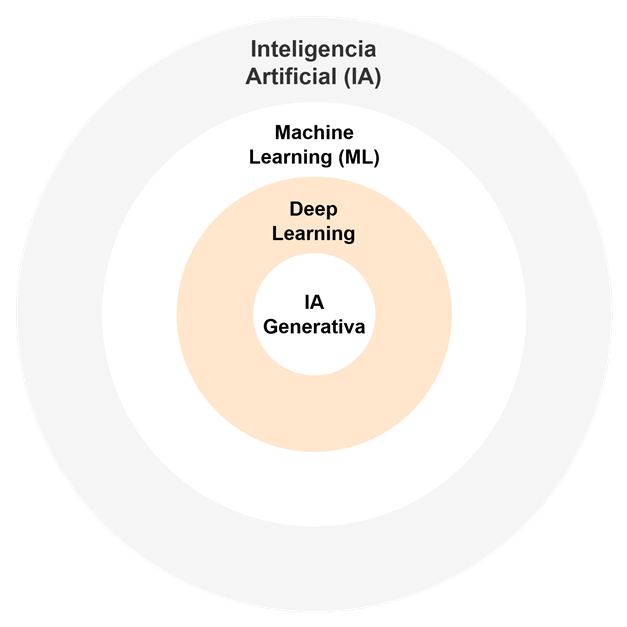
Cuando hablamos de inteligencia artificial, conviene poner las cosas en su sitio. La IA (Inteligencia Artificial) es el concepto general: sistemas capaces de razonar, aprender y reconocer patrones.
Dentro de ese universo, el Machine Learning es el motor principal, porque permite que un sistema aprenda a partir de los datos sin programar cada regla a mano. A partir de ahí aparecen enfoques más avanzados, como el Deep Learning, apoyado en redes neuronales profundas para resolver problemas especialmente complejos, o la IA generativa, capaz de crear texto, imágenes, videos o código con una naturalidad impensable hace pocos años.
Cómo aprenden los modelos de Machine Learning
La capacidad de un modelo para aprender, generalizar y tomar buenas decisiones depende directamente de la calidad, la cantidad y el tipo de datos que recibe. En términos generales, esos datos pueden estar etiquetados, cuando conocemos de antemano el resultado esperado, o no etiquetados, cuando el sistema debe descubrir patrones por sí mismo.
En el caso de los datos etiquetados, se trata de conjuntos de datos en los que cada ejemplo ya incluye la respuesta correcta o la categoría esperada. Por ejemplo, imágenes acompañadas de la indicación “fraude” o “no fraude”, correos clasificados como “spam” o “legítimo”, o registros históricos donde el resultado final es conocido. Estas etiquetas sirven como referencia para que el modelo aprenda qué patrones se asocian a cada resultado.
En el aprendizaje supervisado, el modelo aprende a partir de ejemplos claros y datos etiquetados. Es el enfoque más habitual cuando se trata de clasificar información o predecir valores concretos.
En el aprendizaje no supervisado, el sistema descubre patrones por sí mismo en conjuntos de datos sin etiquetas. Resulta especialmente útil para segmentar clientes o detectar comportamientos anómalos.
En el aprendizaje por refuerzo, el modelo optimiza sus decisiones mediante un esquema de prueba y error basado en recompensas y penalizaciones. Es clave en escenarios más complejos y dinámicos, como motores de recomendación que evolucionan con la interacción real de los usuarios.
¿Tiene sentido usar IA?
No todo problema necesita inteligencia artificial, y aquí aparece uno de los errores más frecuentes. Si una lógica es estable, clara y no cambia con el tiempo, una solución basada en reglas suele ser más simple, más barata y más fácil de mantener. Validar formatos, aplicar políticas fijas o seguir flujos deterministas no requiere modelos entrenados ni pipelines de inteligencia artificial sofisticados.
La IA empieza a aportar valor cuando el problema es dinámico, cuando los patrones cambian, cuando los datos crecen y cuando mantener reglas manuales se vuelve inviable. Analizar sentimiento, detectar fraude, anticipar demanda o personalizar experiencias son buenos ejemplos. La regla es simple: si el sistema necesita aprender y adaptarse, la IA tiene sentido; si no, probablemente no.
Riesgos y desafíos al llevar modelos a producción
Cuando se da ese paso, entran en juego nuevos desafíos. Un modelo puede funcionar muy bien en pruebas y fallar estrepitosamente en el mundo real. A veces esto ocurre por sobreajuste (overfitting), cuando aprende “demasiado” de los datos de entrenamiento y no logra generalizar. En el extremo opuesto está el subajuste (underfitting), donde el modelo es demasiado simple y no capta los patrones relevantes. Y, en escenarios más delicados, aparece el sesgo (bias): si los datos de entrenamiento están desequilibrados o reflejan desigualdades, el modelo las reproducirá, con impactos técnicos, éticos, legales y reputacionales.
Medir bien para tomar mejores decisiones
Medir bien es tan importante como entrenar bien. No todas las métricas sirven para todos los casos: en algunos escenarios, equivocarse de más es aceptable; en otros, un solo error tiene un coste enorme.

The exactitud (accuracy) mide cuántas predicciones fueron correctas en general y funciona bien cuando los datos están balanceados. La precisión indica qué tan confiables son las predicciones positivas del modelo, algo crítico cuando un falso positivo genera fricción o costes innecesarios.
El recall mide la capacidad del modelo para no dejar pasar casos importantes, algo clave cuando un falso negativo es inaceptable, como en fraudes o fallos críticos. En modelos de predicción numérica, las métricas de error reflejan qué tan lejos están las predicciones del valor real, en las mismas unidades del negocio, como dinero, volumen o demanda. Elegir la métrica correcta no es una decisión matemática aislada, sino una decisión alineada con el impacto real en el negocio.
MLOps: llevar la IA al mundo real
MLOps es lo que convierte un experimento en una solución operativa. Aplica principios de ingeniería de software al Machine Learning para asegurar que los modelos se entrenan, se despliegan y se mantienen de forma controlada. El ciclo es claro: partir de un objetivo de negocio, preparar los datos correctamente, entrenar y ajustar modelos, evaluarlos con criterios adecuados, desplegarlos de forma segura y monitorizarlos en producción.
Porque un modelo no falla solo cuando da malas predicciones. También falla cuando los datos cambian, cuando los patrones del negocio evolucionan o cuando nadie detecta que ha dejado de ser confiable. La monitorización continua y el reentrenamiento controlado son tan importantes como el entrenamiento inicial.
AWS como plataforma para escalar IA de forma segura
AWS ofrece una plataforma muy sólida para cubrir todo este ciclo sin necesidad de construir cada pieza desde cero. Incluye servicios para preparar y etiquetar datos, herramientas para orquestar pipelines completos, opciones para desplegar modelos en tiempo real o por lotes y capacidades para monitorizar su comportamiento en producción. Bien utilizados, estos servicios permiten escalar proyectos de IA con orden, trazabilidad y gobernanza.
Preguntas frecuentes sobre adopción estratégica de la inteligencia artificial
La inteligencia artificial es el concepto general que engloba sistemas capaces de razonar, aprender y reconocer patrones. Dentro de ese marco, el Machine Learning permite que los modelos aprendan a partir de datos sin programar cada regla manualmente. El Deep Learning es una rama más avanzada del Machine Learning basada en redes neuronales profundas, especialmente útil en problemas complejos. Por su parte, la IA generativa se centra en crear contenido nuevo, como texto, imágenes, vídeo o código.
La inteligencia artificial tiene sentido cuando el problema es dinámico, los patrones cambian con el tiempo, el volumen de datos crece y mantener reglas manuales deja de ser viable. Casos como la detección de fraude, la predicción de demanda, el análisis de sentimiento o la personalización de experiencias suelen encajar bien. En cambio, si la lógica es estable y determinista, una solución basada en reglas puede ser más adecuada.
Un proyecto de Machine Learning necesita datos de calidad, en cantidad suficiente y alineados con el caso de uso. Estos datos pueden estar etiquetados, si ya incluyen el resultado esperado, o no etiquetados, si el sistema debe descubrir patrones por sí mismo. La calidad del dato influye directamente en la capacidad del modelo para aprender, generalizar y ofrecer resultados útiles para el negocio.
Uno de los principales riesgos es que el modelo funcione bien en pruebas pero falle en entornos reales. Esto puede ocurrir por sobreajuste, subajuste o sesgos en los datos de entrenamiento. También existe el riesgo de que el modelo pierda fiabilidad cuando cambian los datos o evoluciona el contexto de negocio. Por eso es fundamental monitorizar su comportamiento y establecer procesos de reentrenamiento controlado.
MLOps permite convertir un experimento en una solución operativa y sostenible. Aplica principios de ingeniería al ciclo de vida del Machine Learning para entrenar, desplegar, monitorizar y mantener modelos de forma controlada. Esto mejora la trazabilidad, reduce errores operativos y facilita que la inteligencia artificial genere valor real en producción, no solo en entornos de prueba.
AWS proporciona servicios para preparar y etiquetar datos, orquestar pipelines, desplegar modelos en tiempo real o por lotes y monitorizar su rendimiento en producción. Esto permite escalar proyectos de inteligencia artificial con mayor orden, seguridad y gobernanza, sin necesidad de construir toda la infraestructura desde cero.
De los fundamentos a la acción
Entender estos fundamentos es el primer paso para una adopción estratégica de la inteligencia artificial con criterio.
Si está evaluando cómo aplicar Machine Learning o IA generativa en su organización, el punto de partida es una estrategia bien diseñada. En Hopla! acompañamos ese proceso, desde la definición del caso de uso hasta la operación en producción, asegurando que la inversión en la nube se traduzca en valor concreto para el negocio.
¿Quiere identificar un caso de uso viable y llevarlo a producción con garantías? Contáctenos y le ayudamos a definir la estrategia, validar el caso de uso y escalar el modelo con control, seguridad y foco en negocio.


