

Diseñar una arquitectura de base de datos sólida implica anticiparse a las futuras necesidades del negocio y funcionales del sistema. En soluciones que requieren alta disponibilidad en PostgreSQL (HA), este proceso debe ser aún más cuidadoso, buscando equilibrio entre resiliencia, simplicidad y coste.
En el ámbito tecnológico, la alta disponibilidad suele lograrse mediante la duplicación de componentes críticos. El objetivo es garantizar continuidad operativa, incluso en caso de fallos, sin invertir en exceso en infraestructura que rara vez será utilizada.
¿Qué es la alta disponibilidad en PostgreSQL?
Alta disponibilidad significa que un sistema puede seguir siendo accesible y operativo aunque falle alguno de sus componentes. En una base de datos, esto implica que los datos deben estar disponibles durante tareas de mantenimiento y en situaciones imprevistas.
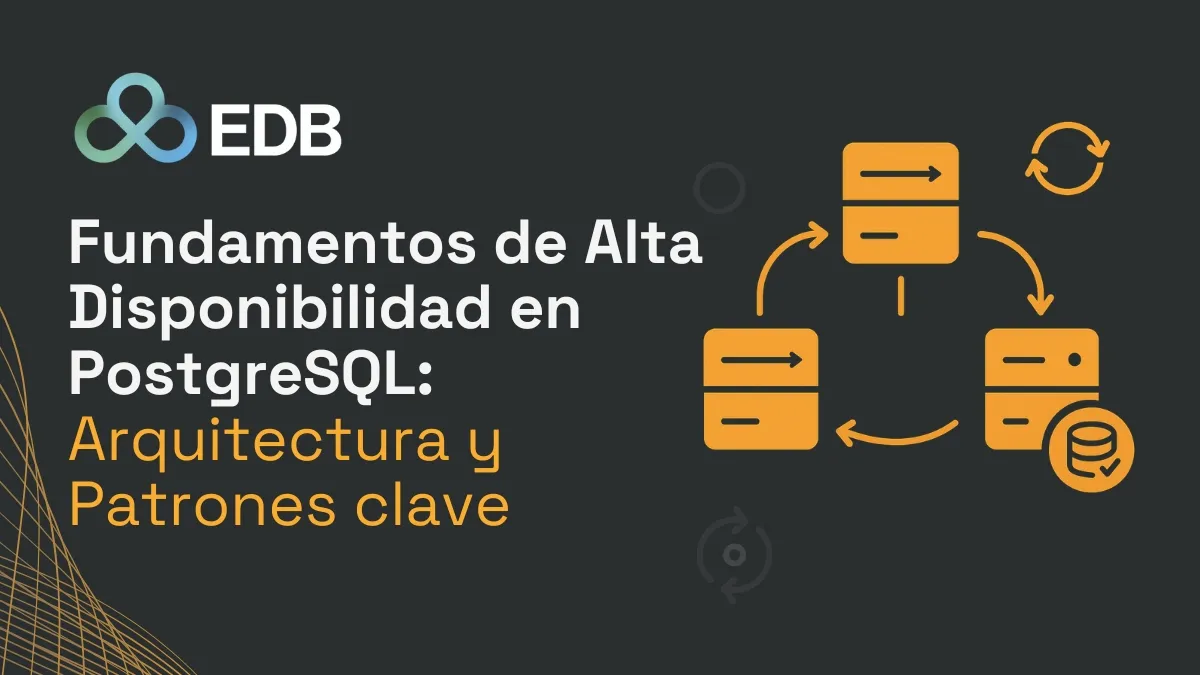
Dos métricas son clave para definir una estrategia de HA:
- RTO (Recovery Time Objective): Tiempo máximo que puede estar fuera de servicio el sistema antes de restaurarse completamente.
- RPO (Recovery Point Objective): Cantidad máxima de datos que podrían perderse desde el último respaldo válido hasta el momento del fallo.
Reducir a cero cualquiera de estas métricas incrementa notablemente los costes y la complejidad, por lo que deben ajustarse de acuerdo con los objetivos del negocio.
PostgreSQL cuenta con herramientas integradas que permiten implementar soluciones de HA a partir de distintos enfoques.
Terminología Clave
- Instancia: Un conjunto de bases de datos administradas por un proceso de PostgreSQL.
- Clúster: Conjunto de instancias redundantes y componentes auxiliares (como gestores de failover) que conforman una solución HA.
- Nodo: Servidor, físico o virtual, que alberga alguno de los componentes de la solución, como una instancia de PostgreSQL o un sistema de respaldo.
- Ubicación: Puede referirse a una zona de disponibilidad, región o centro de datos. Implementar nodos en varias ubicaciones mejora la tolerancia a fallos regionales.
- Testigo (witness): Nodo adicional que ayuda a alcanzar quórum en decisiones de conmutación por error cuando el número de nodos de base de datos es par.
Estrategias clave para lograr alta disponibilidad en PostgreSQL
Recuperación a un Punto en el Tiempo (PITR)
La recuperación desde una copia de seguridad hasta un punto específico puede ser útil si se ajusta al RTO y RPO definidos. Este enfoque se basa en restaurar datos respaldados y aplicar archivos WAL hasta alcanzar el estado deseado. Cuanto más frecuentes los respaldos WAL, menor será la pérdida potencial de datos.
Replicación
PostgreSQL ofrece replicación física y lógica. Además, existen soluciones extendidas como EDB Postgres Distributed (PGD) que mejoran las capacidades de la replicación lógica para entornos críticos.
Replicación Física
Consiste en copiar archivos WAL desde el servidor principal a los servidores réplica. Puede ser:
- Por archivo: se archivan y recuperan WALs desde un almacenamiento compartido.
- En streaming: las réplicas están conectadas y reciben WALs en tiempo real.
Ventajas:
- Configuración sencilla
- Replica estructuras y datos
- Alta eficiencia
- Baja carga en el nodo principal
Limitaciones:
- No permite filtrado o transformación de datos
- Requiere versiones idénticas de PostgreSQL
Replicación Lógica
Captura cambios a nivel de tabla y los transmite como instrucciones.
Ventajas:
- Filtrado y transformación de datos
- Compatible entre distintas versiones de PostgreSQL
- Permite escritura en réplicas
Desventajas:
- Mayor carga en el servidor
- Posibles conflictos de datos
- No replica cambios de esquema automáticamente
EDB Postgres Distributed
Amplía la replicación lógica añadiendo replicación de DDL, resolución de conflictos y mayor consistencia entre réplicas. Ideal para entornos distribuidos y exigentes.
¿Cuándo usar cada tipo?
- Replicación física: ideal para alta disponibilidad, recuperación ante desastres y escalado de consultas de solo lectura.
- Replicación lógica: útil en integración de datos, entornos de pruebas, y sincronización entre versiones.
- EDB Postgres Distributed: combina las ventajas de ambas, ofreciendo robustez, flexibilidad y gestión automática.
Clústeres con Conmutación por Error
Herramientas como Patroni, repmgr o EDB Failover Manager permiten automatizar la promoción de réplicas cuando el nodo principal falla, simplificando el mantenimiento y reduciendo el tiempo de inactividad. PGD ya incorpora esta funcionalidad, eliminando la necesidad de herramientas externas.
Balanceo de Carga
Distribuir las consultas entre múltiples nodos reduce la carga del servidor principal y aumenta la disponibilidad. HAProxy, por ejemplo, puede dirigir conexiones de manera inteligente, incluso tras conmutaciones por error.
Respaldo y Recuperación
Las copias de seguridad periódicas son esenciales para cualquier estrategia de HA. PostgreSQL permite hacer respaldos físicos, lógicos y por snapshots. Herramientas como Barman o pgBackRest facilitan la gestión de respaldos y archivos WAL para recuperación.
Agrupadores de Conexión
PgBouncer y Pgpool-II optimizan el uso de conexiones a la base de datos y permiten redirigirlas en caso de conmutación por error, reduciendo la sobrecarga en entornos de alta demanda.
Buenas Prácticas
- Supervisión activa: Use herramientas como Prometheus, Grafana o Postgres Enterprise Manager para monitorear el estado y rendimiento del sistema.
- Pruebas periódicas de failover: Ensaye escenarios de fallo para validar que los procesos de recuperación funcionan correctamente.
- Documentación clara: Tener procedimientos bien documentados acelera la resolución de incidencias.
Patrones arquitectónicos para alta disponibilidad en PostgreSQL según necesidades del negocio
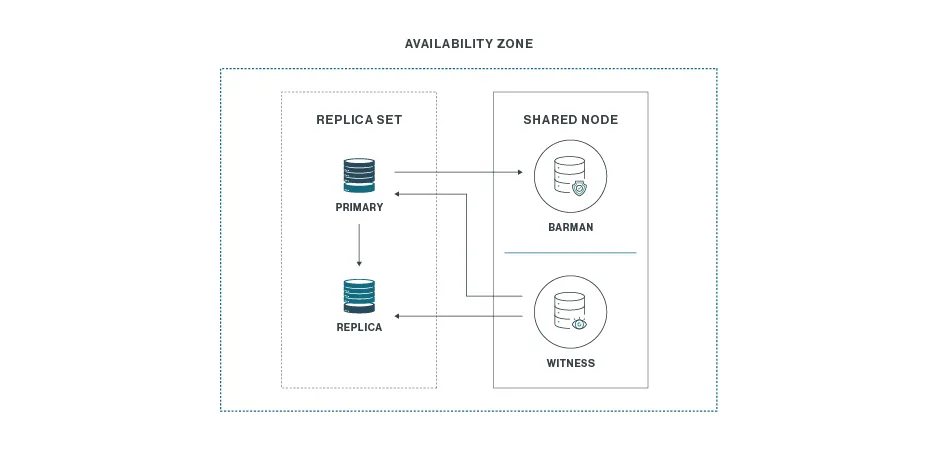
One by Three
Una sola ubicación con tres nodos: uno principal, una réplica, y un nodo mixto que actúa como testigo y ejecuta respaldos. Es la opción más económica, aunque no protege contra fallos regionales.
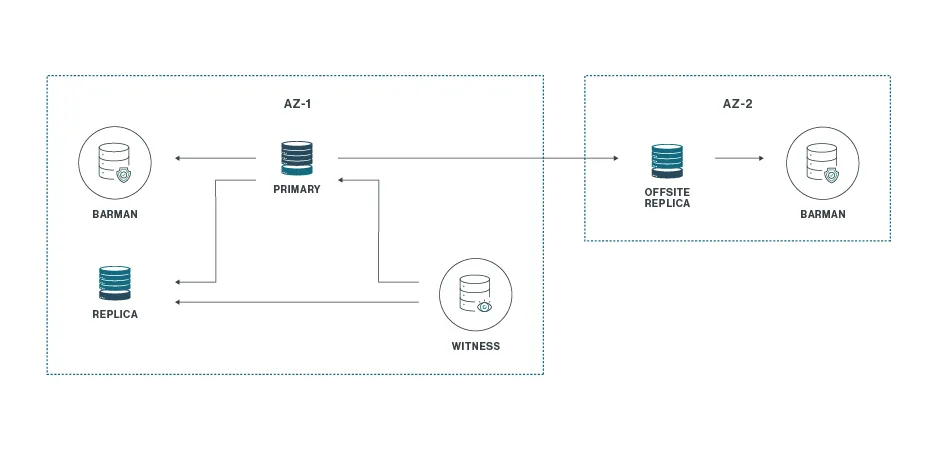
One by Three Plus One
Extiende el modelo anterior añadiendo una réplica en una segunda ubicación. Mejora la resiliencia frente a desastres regionales, aunque requiere intervención manual para recuperar la operación completa.
Two by Three Plus One
Diseño distribuido con alta disponibilidad real y recuperación automática ante pérdida de una ubicación completa. Requiere tres ubicaciones y más recursos, pero ofrece el mayor nivel de resiliencia.
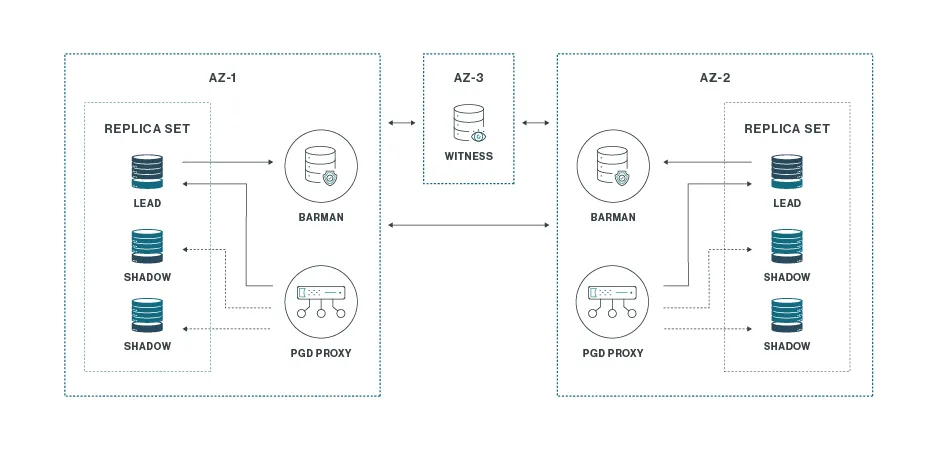
Cada patrón debe adaptarse a las necesidades del negocio, presupuesto disponible y tolerancia al riesgo. PostgreSQL, junto con herramientas especializadas, permite construir soluciones de alta disponibilidad.
No dude en contactarse aquí para obtener las mejores soluciones para su empresa.


