


Índice
- Introducción
Plataforma de datos en memoria unificada: funcionalidades clave
- Almacén de características en tiempo real (Feature Store)
- Búsqueda vectorial y datos no estructurados
- Caché de predicciones y gestión de modelos ML
Caso de uso: Predicción de glucosa en tiempo real (Healthcare)
- Conclusión
- Referencias
Introducción
The IA en tiempo real requiere acceso a datos con latencias de milisegundos o menores para poder alimentar modelos de machine learning al instante. Esto implica recuperar rápidamente insumos como las características (features) del modelo, vectores de embeddings para consultas semánticas, contexto específico del usuario o empresa (p. ej. para enriquecer prompts a modelos de lenguaje), así como utilizar cachés de predicciones que eviten cálculos repetitivos y permitir la carga dinámica de modelos bajo demanda.
En arquitecturas tradicionales, estas funciones suelen estar repartidas en múltiples sistemas independientes (feature stores, bases de datos vectoriales, cachés en memoria, repositorios de modelos, etc.), lo cual añade complejidad y aumenta la latencia en los flujos de inferencia. GridGain for AI surge para resolver este desafío unificando todas esas capacidades en una sola plataforma de datos distribuida en memoria, logrando un rendimiento de latencia ultrabaja, escalabilidad horizontal transparente y menor sobrecarga de integración; en definitiva, simplifica las implementaciones y mejora la eficiencia de los sistemas de IA modernos.
Esta plataforma, creada por los desarrolladores originales de Apache Ignite, adopta una arquitectura memory-first (prioridad a memoria) con cómputo colocalizado, capaz de procesar datos y ejecutar analíticas con latencias de milisegundo, a la vez que opcionalmente persiste en disco los datos para mayor durabilidad.
En los siguientes apartados detallaremos cómo una plataforma unificada en memoria como GridGain aborda las distintas necesidades de la IA en tiempo real, y presentaremos un caso práctico de uso en el sector salud.
Plataforma de datos en memoria unificada: funcionalidades clave
Arquitectura de IA predictiva tradicional vs. unificada. En los sistemas de IA predictiva convencionales se despliegan por separado múltiples componentes de almacenamiento: un feature store para las características de ML, una base de datos vectorial para embeddings, un repositorio de modelos para gestionar versiones de ML, y cachés de inferencias para acelerar respuestas. GridGain simplifica este ecosistema unificando feature store, búsqueda vectorial, repositorio de modelos y caché en una sola plataforma en memoria.
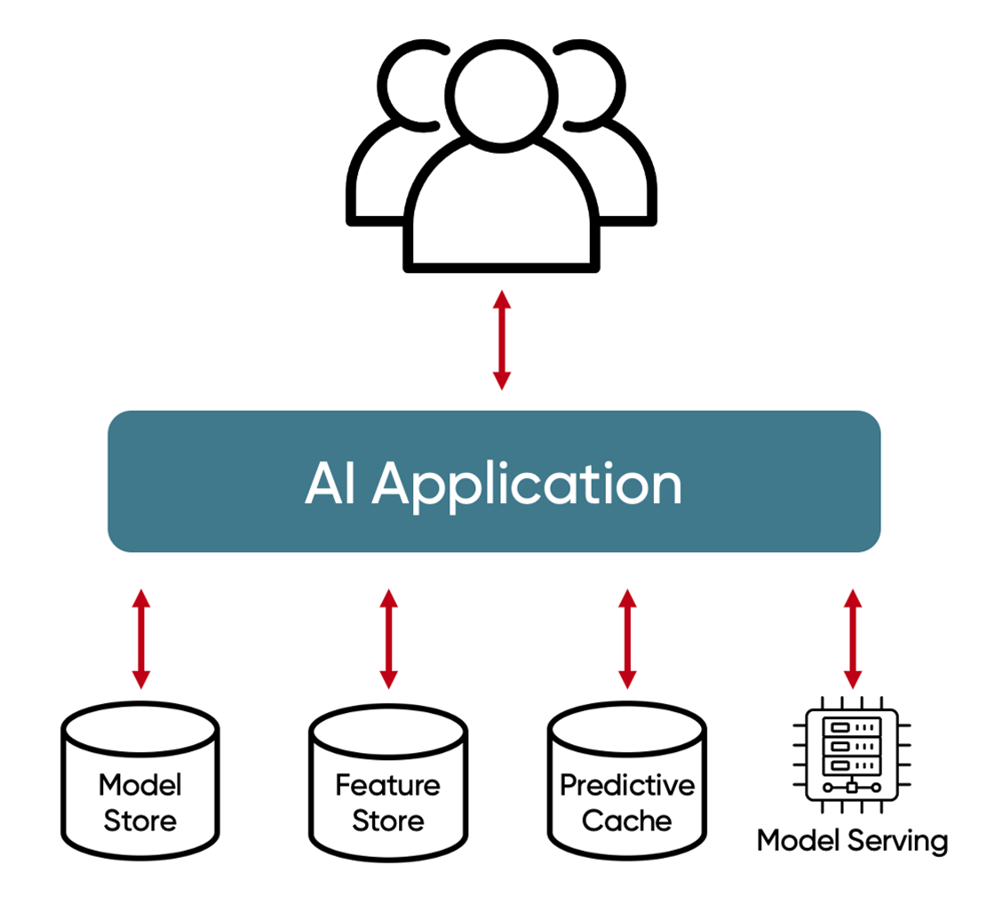
Almacén de características en tiempo real (Feature Store)
Un feature store es un repositorio centralizado donde se preparan y organizan las características usadas por los modelos de ML. GridGain puede actuar como feature store online debido a su arquitectura en memoria distribuida: ofrece accesos de muy baja latencia (sub-milisegundo) a las features, algo crítico para alimentar modelos de inferencia en producción sin demoras perceptibles.
Además de servir valores de características ya calculados, GridGain permite extraer nuevas características en tiempo real a partir de datos de streaming o transaccionales, incorporando información fresca para la predicción sobre la marcha.
Para la gestión del ciclo de vida de las features, la plataforma se integra con herramientas populares como Feast, un feature store de código abierto, facilitando la sincronización entre el almacenamiento offline (usado en entrenamiento batch) y el online en GridGain.
En resumen, GridGain aporta un backend de feature store con velocidad en memoria, escalabilidad horizontal para altos volúmenes y alta disponibilidad, eliminando cuellos de botella al servir los datos de entrada del modelo en tiempo real.
Búsqueda vectorial y datos no estructurados
En aplicaciones de IA generativa y sistemas que manejan datos no estructurados (texto, embeddings, multimedia), es indispensable contar con almacenamiento especializado para vectores y capacidades de búsqueda semántica. GridGain aborda esta necesidad mediante una base de datos vectorial en memoria integrada, soportando búsqueda vectorial (vector search) de alta eficiencia sobre grandes colecciones de embeddings.
Esto permite, por ejemplo, almacenar representaciones vectoriales de documentos o imágenes y recuperarlos por similitud en cuestión de milisegundos, habilitando patrones como la búsqueda semántica y la generación de texto aumentada con recuperación de datos (el patrón Retrieval-Augmented Generation, RAG) sobre datos empresariales.
Complementariamente, la plataforma incorpora un motor de búsqueda de texto completo y consultas SQL distribuidas, de modo que tanto los datos no estructurados como los estructurados pueden convivir y consultarse eficientemente dentro del mismo sistema unificado
Gracias a estas funcionalidades, GridGain puede desempeñarse como base unificada de conocimiento para alimentar modelos de lenguaje grandes (LLMs): actúa a la vez como almacén vectorial de embeddings, como memoria de conversaciones (historial de chat) y como caché semántica de respuestas ya generadas.
De hecho, GridGain se integra nativamente con frameworks de IA generativa como LangChain y Langflow, lo que permite usarlo directamente como backend para vectores, memoria de diálogo o caché de LLM dentro de esas librerías.
Esta versatilidad simplifica la incorporación de datos empresariales en aplicaciones de IA generativa en tiempo real, todo ello manteniendo la rapidez de respuesta gracias al procesamiento en memoria.
Caché de predicciones y gestión de modelos ML
Otra pieza fundamental para la IA en producción es la caché de predicciones: un almacenamiento rápido de resultados de inferencias ya calculados, para reutilizarlos en futuras consultas similares y así reducir la carga de cómputo. GridGain, con su almacén distribuido en RAM, está muy bien posicionado para este rol, puede almacenar y servir miles de predicciones precalculadas con latencias de milisegundos, escalando transparentemente a más nodos si la carga crece.
Por ejemplo, en casos de uso como recomendadores en línea o detección de fraude, las predicciones recientes (o las respuestas de un LLM) pueden mantenerse en la caché en memoria y devolverse inmediatamente si se repiten las mismas consultas, ahorrando costosos reprocesamientos.
Adicionalmente, la plataforma puede actuar como repositorio de modelos en tiempo de ejecución, almacenando los binarios o parámetros de modelos de ML entrenados (versionados) y permitiendo su acceso ultrarrápido para la inferencia. La arquitectura de GridGain está diseñada para entregar modelos y datos con alta eficiencia, lo cual reduce la latencia total de inferencia incluso cuando se requiere cargar modelos complejos sobre la marcha.
Es más, gracias a la capacidad de cómputo colocalizado, GridGain posibilita ejecutar modelos predictivos directamente donde residen los datos, es decir, realizar inferencias in-situ en los nodos del cluster en memoria. Este enfoque elimina la necesidad de mover datos a un servicio externo de serving de ML, simplificando la arquitectura y ganando velocidad.
En suma, unificando en un solo sistema la caché de resultados y el almacenamiento/ejecución de modelos, se agiliza enormemente el ciclo completo de inferencia de AI: desde la obtención de features hasta la entrega de la predicción final.
Caso de uso: Predicción de glucosa en tiempo real (Healthcare)
Arquitectura unificada para predicción de glucemia con GridGain. En este ejemplo de salud conectado, GridGain (Apache Ignite) actúa como núcleo de datos en memoria, integrándose con Feast como catálogo de features, Apache Kafka como sistema de ingesta de datos de sensores CGM, y un modelo de ML que consume dichas características para inferir los niveles de glucosa futuros de cada paciente.
Podemos expandir la información en: https://github.com/GridGain-Demos/ignite_feast_cgm_demo
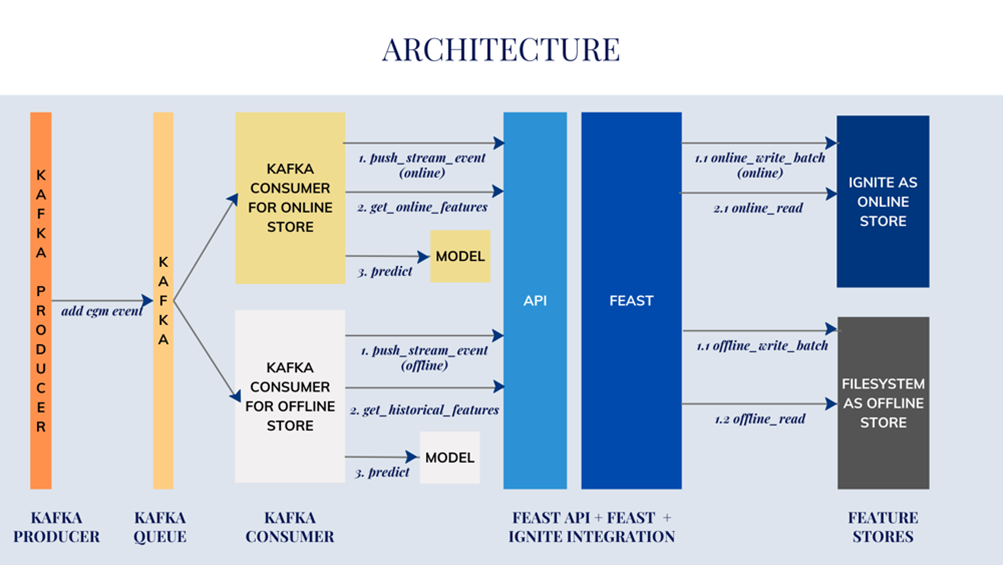
Un caso práctico que ejemplifica los beneficios de esta arquitectura es un sistema de monitorización continua de glucosa (CGM, Continuous Glucose Monitoring) para pacientes diabéticos. El objetivo de este sistema es predecir los niveles de glucosa en sangre con unos minutos de antelación, de forma personalizada y en tiempo real, para así anticipar eventos de hipoglucemia/hiperglucemia y posibilitar intervenciones proactivas.
En una demostración reciente de esta solución, GridGain se empleó como feature store online de alta velocidad para servir las características del paciente al modelo de predicción, aprovechando sus capacidades de baja latencia en memoria. La plataforma GridGain/Ignite se integró con Feast (que manejaba la definición y versión de las features, así como la sincronización con un almacén histórico) y con Apache Kafka (encargado de ingerir en streaming las lecturas de glucosa desde los dispositivos sensores).
Procesamiento en streaming y predicción en tiempo real
Conforme llegaban nuevos datos de glucosa vía Kafka, un consumidor los procesaba en tiempo real: calculaba características agregadas (ej. tendencia, hora del día, día de la semana) y las almacenaba en GridGain/Feast, invocaba al modelo de predicción de glucosa entrenado para obtener el pronóstico a 15-30 minutos, y enviaba dichas predicciones a un panel en la clínica o aplicación móvil del paciente. El modelo ML incorporaba tanto datos históricos del paciente (almacenados en un repositorio offline, p. ej. en archivos Parquet o Snowflake) como las lecturas en tiempo real que iban llegando, combinando así contexto histórico y actual para afinar la predicción.
La ventaja de esta solución unificada se reflejó en el desempeño: las características requeridas podían consultarse con latencias sub-milisegundo y las predicciones se actualizaban instantáneamente con cada nueva lectura del sensor, gracias al procesamiento en memoria. Incluso bajo alta frecuencia de datos, el sistema mantenía respuesta en tiempo real sin degradación.
Asimismo, la arquitectura distribuida de GridGain aportó escalabilidad horizontal (permitiendo añadir nodos para manejar más pacientes o más frecuencia de datos) y alta disponibilidad mediante replicación de datos entre nodos, eliminando puntos únicos de falla. Estos factores son críticos en entornos sanitarios donde cada segundo cuenta. En resumen, el caso de la predicción de glucosa mostró cómo una plataforma de datos en memoria unificada puede integrar flujos de datos históricos y en streaming, servir features y embeddings, y alojar la lógica de inferencia ML en un único ecosistema altamente performant, haciendo posible una IA en tiempo real que anteriormente requería orquestar múltiples sistemas dispares.
Conclusión
Adoptar una plataforma unificada de datos en memoria para soportar cargas de IA en tiempo real conlleva importantes beneficios. En primer lugar, minimiza la latencia de acceso a datos para los modelos: todas las características, vectores e información de contexto se obtienen directamente desde memoria en milisegundos, permitiendo generar predicciones al instante.
En segundo lugar, simplifica la arquitectura drásticamente al eliminar la necesidad de mantener y sincronizar varios sistemas especializados (feature store, base vectorial, caché, etc.), reduciendo la complejidad operativa y los costos asociados. Esta simplificación también conlleva una mayor escalabilidad y flexibilidad: al crecer la demanda, se escala un único clúster integrado en lugar de tener que coordinar el escalado de múltiples plataformas.
Adicionalmente, al unificar almacenamiento y computación en una misma capa, se evitan los cuellos de botella de transferir datos entre sistemas, mejorando la eficiencia global de las inferencias. Por último, al ser una solución memory-first con opciones de persistencia, se logra un equilibrio óptimo entre rendimiento y resiliencia de los datos según los requerimientos de cada caso de uso.
En conjunto, una plataforma de datos en memoria unificada como GridGain acelera el paso de la experimentación a la producción en proyectos de IA. Las empresas pueden obtener antes el valor de sus modelos al contar con una infraestructura de datos capaz de responder en tiempo real. Organizaciones especializadas como Hopla acompañan a las compañías en la implantación de este tipo de soluciones, aportando experiencia tanto en GridGain como en arquitecturas de datos y ML. Así, al adoptar tecnologías de datos en memoria unificadas, las organizaciones quedan preparadas para afrontar casos de uso avanzados, desde fraud detection en milisegundos hasta recomendaciones personalizadas inmediatas o aplicaciones de IA generativa integradas en sus productos, manteniendo siempre la velocidad, escalabilidad y confiabilidad que exigen los entornos de misión crítica.
Referencias
Título Página Separador Título del sitio
- GridGain Press Release (Feb 2025) – “GridGain Enables Real-Time AI with Enhanced Vector Store, Feature Store Capabilities.” GridGain Official News.
- GridGain Tutorial (Dec 2025) – “Low-Latency Machine Learning Feature Store with GridGain and Feast.” GridGain Documentation (Manini Puranik).
- GridGain Blog (Feb 2025) – “Using GridGain for AI as a Unified Data Store for Online AI Applications.” GridGain Blog (Stanislav Lukyanov).
- GridGain Press Release (May 2025) – “GridGain Bolsters Support for Real-Time AI and Analytics.” GridGain Official News.
- GridGain Demo Repository (2025) – “ignite_feast_cgm_demo” (GitHub – ejemplo de integración Feast + Ignite para predicción de glucosa)


