

Garanticemos la resiliencia de un clúster Postgres
Los pilares fundamentales en los sistemas de bases de datos son la disponibilidad y la integridad de los datos para cualquier organización, por tanto, disponer de alta disponibilidad automatizada es esencial. Los cortes de servicio, no planificados, en entornos de producción, pueden provocar pérdidas de información, largos tiempo de inactividad y malestar en los clientes.
Entre los numerosos sistemas de bases de datos, cabe destacar, PostgreSQL, uno de los sistemas de gestión de bases de datos, Opensource, más robustos y versátiles. Su capacidad para manejar cargas de trabajo exigentes, soportar un amplio rango de tipos de datos y extensiones, ha permitido el uso de PostgreSQL, como motor de base de datos principal.
En este contexto, no se puede pasar por alto, que PostgreSQL no dispone de forma nativa de failover automático, por lo que es necesario recurrir a herramientas de terceros para disponer de esta funcionalidad. No obstante, debido a que la alta disponibilidad es una necesidad frecuente, tanto las comunidades como empresas privadas han desarrollado diferentes herramientas que permiten desplegar PostgreSQL con alta disponibilidad. En este blog analizaremos algunas de las ventajas y/o funcionalidades de la herramienta OpenSource, Patroni y de los componentes a tener en cuenta durante un despliegue.
Patroni
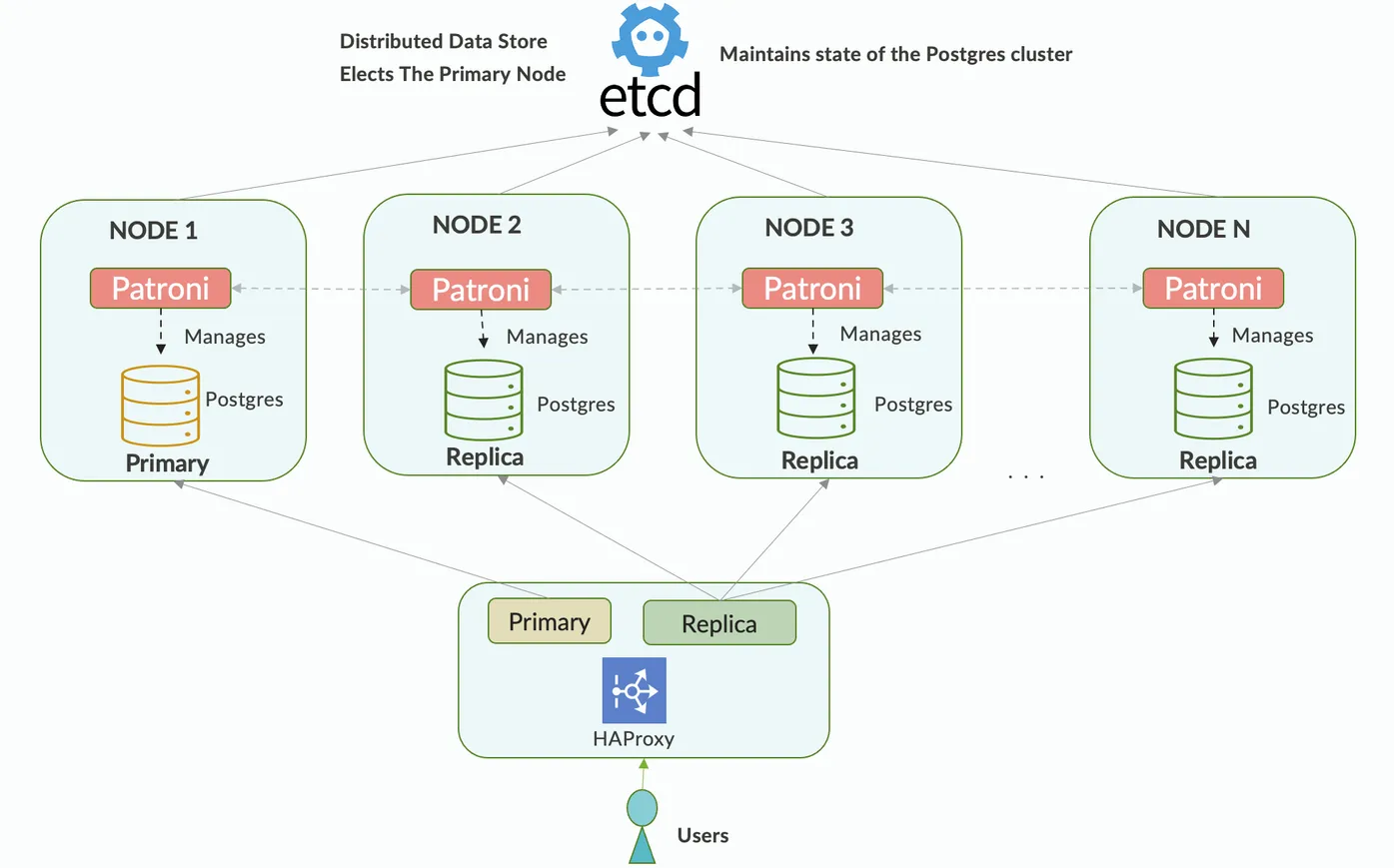
Patroni, permite administrar y mantener clústers de Postgres de alta disponibilidad. Está escrita en python y requiere del almacén, etcd, para guardar la información del cluster de forma dinámica y en tiempo real. El uso de Patroni permite disponer de las siguientes funcionalidades:
- Líder (o primario) automático: Patroni selecciona automáticamente un servidor líder (o primario) dentro del clúster de Postgres.
- Detección y recuperación ante fallos: Patroni detecta los fallos e implementa medidas para recuperar el clúster.
- Escalabilidad flexible: La escalabilidad es flexible dado que se pueden agregar nuevos esclavos sincronizados con el líder.
- Configuración dinámica: El uso de etcd permite distribuir la configuración de forma dinámica.
Ejemplo de despliegue de Patroni
Aunque hay diferentes arquitecturas para el despliegue de Patroni, una de las más habituales es desplegar tres servicios Patroni, en tres servidores diferentes; tres servicios etcd, en los mismos servidores que Patroni, para reutilizar y minimizar recursos o separarlos en otros tres servidores, y por último, dos servicios de HAProxy.
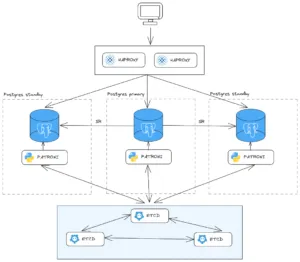
El uso del etcd es clave para que Patroni guarde la información de configuración y sincronice dicha información con el resto de nodos de Patroni, otras alternativas al uso del etcd son ZooKeeper, Consul or Kubernetes, a valorar dependiente del entorno y de las necesidades. Así mismo, HAProxy es un balanceador de carga Opensource, que permitirá acceder a la base de datos primaria de forma transparente y desde un único punto.
Esperamos que hayáis disfrutado de este breve vistazo al fascinante mundo de Patroni. Si os ha gustado y estáis interesados en explorar un ejemplo práctico en acción, no dudéis en quedaros atentos a nuestro Blog. En él, desglosaremos el detalle de un despliegue y te mostraremos cómo combinar Patroni, etcd y HAProxy para formar una infraestructura robusta, que garantice la continuidad del servicio de Postgres e incluso en circunstancias adversas.
¡MantenEos al tanto para descubrir cómo Patroni puede marcar la diferencia!


