


El modelo de lenguaje es solo el principio
Existe un malentendido muy extendido entre los equipos de tecnología que se acercan por primera vez a la inteligencia artificial generativa: creer que basta con llamar a la API de un modelo de lenguaje para tener una solución de IA lista para producción. El modelo responde preguntas, pero en un entorno empresarial real responder preguntas es solo el punto de partida.
Un sistema de IA que realmente aporte valor en producción necesita:
- Consultar la base de datos de clientes antes de responder.
- Crear un ticket en el sistema de incidencias cuando detecta un problema.
- Buscar disponibilidad en el calendario antes de proponer una reunión.
- Recordar el contexto de conversaciones anteriores.
- Escalar automáticamente cuando la situación supera su capacidad de resolución.
Nada de esto viene de serie con un modelo de lenguaje. Todo esto se construye sobre una capa de orquestación.
Es aquí donde entra LangChain: el framework de orquestación de IA escrito en Python más adoptado en el ecosistema enterprise, con más de 100.000 repositorios que lo utilizan y una comunidad activa de más de 3.000 contribuidores. LangChain no es un modelo ni un proveedor de LLMs: es la capa de infraestructura que conecta los modelos de lenguaje con el mundo real, con los datos de la empresa, con los sistemas de negocio y con los usuarios.
Este artículo explica los conceptos fundamentales que todo equipo de desarrollo debe dominar antes de construir soluciones de IA robustas, escalables y mantenibles en producción.
Chains y prompts: la unidad mínima de composición
El concepto central de LangChain es la cadena, o chain: una secuencia de pasos que transforma una entrada en una salida. En su forma más simple, una chain conecta un template de prompt con un modelo de lenguaje y un parser de salida. Sin embargo, este patrón aparentemente sencillo tiene implicaciones relevantes para el desarrollo de software.
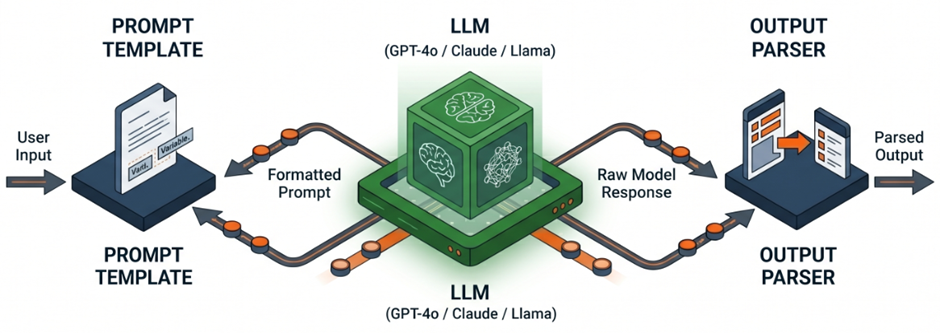
Prompt templates parametrizados
Un prompt template no es texto estático. Es una plantilla parametrizada que recibe variables de contexto —el historial de conversación, el nombre del usuario, los resultados de una búsqueda previa o el rol del agente— y compone dinámicamente la instrucción exacta que el modelo necesita para cada situación específica.
Esta separación entre la lógica de composición del prompt y la ejecución del modelo es lo que permite que las soluciones sean mantenibles, testeables y versionables como cualquier otro componente de software.
Output parsers para respuestas estructuradas
El output parser garantiza que la respuesta del modelo sea estructurada y procesable por el resto del sistema. En producción no basta con texto libre: si el modelo debe devolver una lista de ítems, un objeto JSON con campos específicos, un veredicto categórico o una puntuación numérica, el parser valida y transforma la salida.
Si el modelo produce un formato inesperado, el parser puede lanzar errores estructurados. LangChain incluye parsers nativos para JSON, listas, enumeraciones y estructuras Pydantic personalizadas.
Composabilidad para pipelines multi-etapa
Las chains están diseñadas para encadenarse entre sí: la salida de una puede convertirse directamente en la entrada de la siguiente. Este principio de composabilidad permite construir pipelines complejos y multi-etapa a partir de bloques simples, donde cada componente puede probarse de forma aislada antes de integrarse en el conjunto.
Tools y tool calling: cómo el LLM toma acción sobre sistemas reales
El salto cualitativo de un LLM pasivo a un agente activo llega con el concepto de tool calling. Un LLM moderno —GPT-4o, Claude Sonnet, Gemini o Llama 3— tiene la capacidad nativa de:
- Analizar una solicitud y determinar que necesita información externa o debe ejecutar una acción.
- Emitir una llamada estructurada a una función específica.
- Continuar su razonamiento incorporando los resultados obtenidos.
En LangChain, una tool es cualquier función Python que el modelo puede invocar: buscar en una base de datos vectorial, llamar a una API externa, ejecutar una consulta en el ERP, enviar una notificación a Slack, consultar el inventario en tiempo real o agendar una reunión en Google Calendar.
Lo que distingue este patrón es que el LLM no ejecuta la función directamente. En su lugar, emite una intención estructurada —qué herramienta llamar y con qué parámetros— y el framework ejecuta la función en el servidor, devolviendo los resultados al modelo para que continúe su razonamiento.
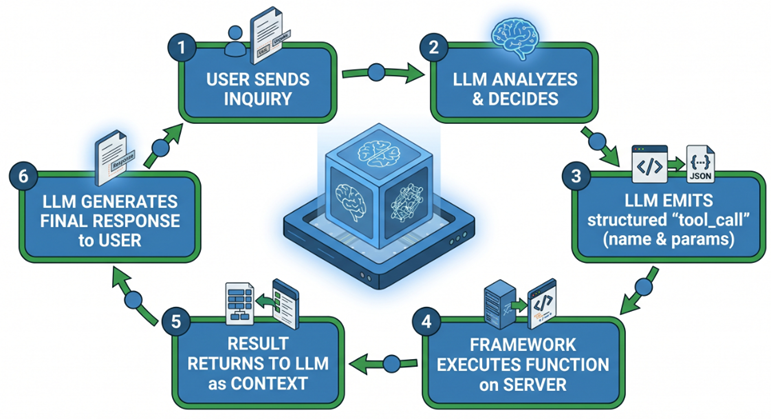
Este patrón tiene implicaciones importantes para el desarrollo enterprise:
Integración transparente con sistemas existentes
El agente puede consultar Salesforce, SAP o cualquier API interna, mientras el usuario final percibe una conversación fluida sin saber que estas acciones están ocurriendo en segundo plano.
Seguridad por diseño
El LLM nunca ejecuta código directamente. El framework controla qué herramientas están disponibles para cada agente, con qué permisos y bajo qué condiciones. Las integraciones con sistemas críticos pueden requerir confirmación humana antes de ejecutarse.
Auditabilidad completa
Cada tool call es registrable en detalle: qué función se invocó, con qué parámetros, qué devolvió, en qué momento y en el contexto de qué conversación. Esta trazabilidad es fundamental para entornos con requisitos de compliance y auditoría.
Memoria de corto plazo: buffer, ventana de contexto y resumen automático
Una conversación con un sistema de IA sin memoria está fundamentalmente rota: el usuario debe repetir el contexto en cada mensaje, la experiencia se degrada y el sistema no puede razonar sobre el historial. LangChain ofrece tres estrategias de memoria conversacional para producción, cada una con un perfil de coste-beneficio diferente.
Buffer memory
Buffer memory almacena el historial completo de la conversación y lo incluye en cada llamada al modelo. Es la estrategia más simple y ofrece la mejor coherencia, pero tiene un coste creciente en tokens conforme la conversación se extiende. Es adecuada para conversaciones cortas o cuando el presupuesto de tokens no es una restricción operativa.
Window memory
Window memory mantiene solo los últimos N mensajes configurables. Reduce el coste de forma predecible, aunque puede perder contexto relevante de mensajes anteriores en conversaciones largas. Es la estrategia correcta para un equilibrio pragmático entre coste y coherencia en la mayoría de los casos de uso enterprise.
Conversation summary memory
Conversation summary memory resuelve el problema de raíz: cuando la conversación supera un umbral configurable de mensajes, el sistema genera automáticamente un resumen comprimido del historial y lo usa como contexto en lugar del historial completo.
De este modo, el modelo no pierde el hilo, el coste en tokens se mantiene acotado y el usuario percibe coherencia sostenida a lo largo de conversaciones largas. Esta estrategia es la base de los sistemas de memoria en agentes de producción.
La elección de estrategia de memoria no es solo un detalle de implementación: tiene impacto directo en el coste operativo mensual y en la calidad percibida por los usuarios. En proyectos enterprise, este diseño debe tratarse como una decisión arquitectónica explícita.
Mensajes multimodales: texto, imágenes y audio en un solo pipeline
Los modelos de lenguaje de última generación son multimodales: procesan texto, imágenes y audio en el mismo pipeline de razonamiento. LangChain abstrae estas capacidades mediante un modelo de mensajes unificado que normaliza diferentes tipos de contenido en un formato estándar para el sistema de orquestación.
Un mensaje en LangChain puede contener múltiples partes en el mismo payload: texto e imagen combinados, transcripciones de audio convertidas a texto, documentos PDF parseados y segmentados automáticamente, o capturas de pantalla para análisis visual.
Esta capacidad abre casos de uso que trascienden el chatbot de texto tradicional:
- Un agente de soporte técnico que analiza capturas de pantalla enviadas por el cliente para diagnosticar el problema antes de responder.
- Un asistente de calidad que compara imágenes de producto contra especificaciones documentadas y genera informes de desviación.
- Un sistema de gestión documental que procesa formularios escaneados y extrae campos estructurados hacia el ERP.
- Un agente de operaciones que analiza grabaciones de llamadas de soporte y genera resúmenes de incidencias categorizados.
La clave es que el pipeline de orquestación no cambia estructuralmente al incorporar nuevas modalidades. La inversión en arquitectura se amortiza: el mismo sistema que hoy procesa texto puede mañana procesar imágenes sin rediseñar la capa de orquestación.
Model Context Protocol (MCP): el estándar emergente para la interoperabilidad de IA
El Model Context Protocol (MCP) es una especificación abierta, promovida por Anthropic y adoptada por los principales actores del ecosistema —incluyendo OpenAI, Google DeepMind y los principales proveedores de herramientas enterprise— que estandariza la forma en que los LLMs se conectan con herramientas y fuentes de datos externas.
Antes de MCP, cada integración entre un LLM y un sistema externo requería código de integración personalizado y específico para cada par formado por el LLM y el sistema. MCP define un contrato de comunicación universal: cualquier sistema que implemente un servidor MCP es automáticamente accesible para cualquier cliente LLM que soporte el protocolo, independientemente del proveedor.
Es para la IA lo que los drivers ODBC fueron para las bases de datos: una estandarización que elimina fragmentación.
LangChain incorpora MCP de forma nativa y con soporte completo. Un servidor MCP puede exponer herramientas mediante dos mecanismos de transporte:
SSE (Server-Sent Events)
El servidor MCP opera como un servicio HTTP accesible en red. El agente se conecta al inicializarse y descubre dinámicamente las herramientas disponibles. Es adecuado para integraciones con servicios externos o sistemas accesibles vía red interna.
STDIO
El servidor MCP opera como un proceso local que se comunica mediante entrada/salida estándar. Es adecuado para herramientas del sistema, scripts propietarios o entornos con restricciones de red estrictas.
La importancia estratégica de MCP para el desarrollo enterprise radica en la reutilización y estandarización: las integraciones construidas hoy como servidores MCP son reutilizables entre proyectos, entre equipos y entre diferentes frameworks de IA, sin rediseño.
El catálogo de servidores MCP disponibles crece diariamente y cubre desde búsqueda web hasta integración con GitHub, Jira, Slack, Google Workspace y sistemas ERP/CRM principales.
Multi-agent systems: cuando la complejidad requiere división del trabajo
Existe un límite para lo que un agente único puede hacer bien de forma simultánea. Un agente de soporte técnico no puede ser experto con igual profundidad en facturación, configuración de producto, escalada legal y política de devoluciones.
La solución es aplicar el mismo principio que se utiliza en los equipos humanos: especialización y coordinación.
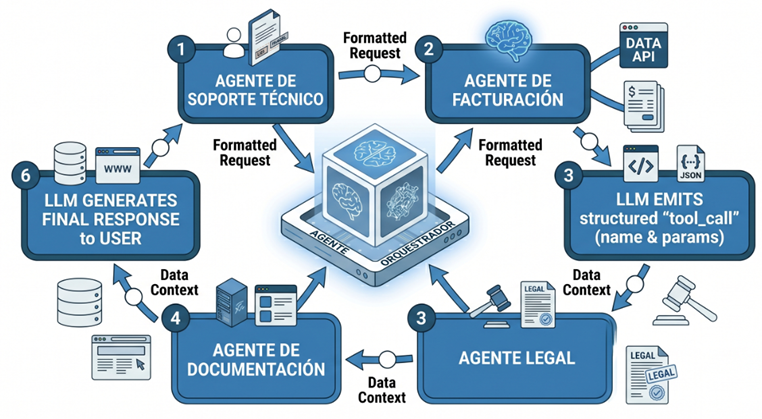
LangChain soporta varios patrones de colaboración entre agentes que se adaptan a distintos escenarios enterprise:
Supervisor pattern
Un agente orquestador recibe la solicitud inicial, determina qué agente especializado es el más adecuado para resolverla, delega la ejecución y consolida los resultados en una respuesta coherente para el usuario. Es el patrón dominante en sistemas de atención al cliente y soporte técnico enterprise.
Routing dinámico por intención
El sistema analiza automáticamente la intención del mensaje —soporte, facturación, información o escalada— y enruta la solicitud a la especialidad correcta, con lógica de fallback al orquestador cuando la clasificación es ambigua.
Colaboración secuencial entre agentes
El primer agente completa su análisis y pasa el resultado enriquecido al siguiente como contexto adicional. Este patrón es natural en flujos de revisión de documentos, generación de informes en múltiples pasos o procesos de aprobación que involucran varias áreas.
La coordinación entre agentes en producción se gestiona con mayor control mediante LangGraph, el framework de orquestación con estado que complementa a LangChain.
Human-in-the-loop: la trampa de la autonomía total
Uno de los errores más frecuentes en proyectos de IA empresarial es diseñar sistemas completamente autónomos sin puntos de control humano. Para muchas operaciones críticas —aprobar una devolución por encima de cierto importe, enviar una comunicación oficial a un cliente en una situación delicada, ejecutar una modificación en una base de datos de producción o comprometer un presupuesto— la autonomía total no es solo un riesgo técnico: también puede ser un riesgo de negocio y, potencialmente, un riesgo regulatorio.
LangChain soporta el patrón human-in-the-loop de forma nativa: el agente puede pausar su ejecución, presentar a un operador humano su razonamiento y la acción que propone tomar, esperar la aprobación o corrección, y continuar con instrucciones ajustadas si el operador lo considera necesario.
Este patrón es especialmente relevante en:
- Flujos de aprobación en compras o contratación por encima de umbrales.
- Respuestas a clientes en situaciones de reclamación o conflicto.
- Acciones con efectos irreversibles sobre sistemas críticos.
- Etapas tempranas de despliegue donde la confianza en el modelo se está calibrando.
La implementación correcta de human-in-the-loop no solo reduce el riesgo operativo. También acelera la adopción interna, porque los equipos operativos mantienen visibilidad y control sobre lo que el sistema hace en su nombre, y pueden intervenir y corregir sin depender del equipo de desarrollo.
LangChain vs. LangGraph: cuándo usar cada uno
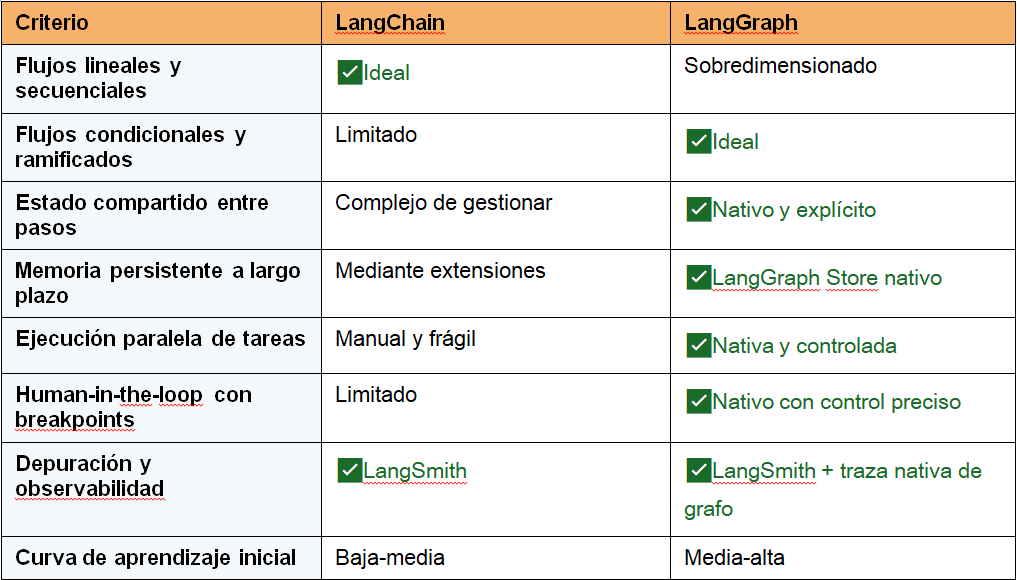
La regla práctica es directa: comience con LangChain. Cuando el flujo deja de ser lineal —cuando necesita condicionales, paralelismo, estado persistente entre pasos o loops controlados— el siguiente paso natural es LangGraph.
Ambos frameworks comparten las mismas abstracciones —tools, memory, prompts y LLMs— y están diseñados para usarse conjuntamente, no como alternativas excluyentes.
La orquestación como ventaja competitiva
Los modelos de lenguaje están evolucionando hacia una commodity. Lo que diferenciará a las organizaciones que lideren la adopción de IA en los próximos años no será solo el proveedor de LLM que elijan, sino la calidad de la capa de orquestación que construyan sobre él.
LangChain proporciona los bloques fundamentales para esa capa: composición de prompts, integración de herramientas con sistemas reales, gestión de memoria conversacional, soporte multimodal, interoperabilidad mediante MCP y patrones de control humano probados en producción.
Dominar estos conceptos no es opcional para los equipos de desarrollo que aspiren a construir soluciones de IA que funcionen en producción y no solo en demos controladas.
Preguntas frecuentes sobre LangChain y la orquestación de IA
Sí. LangChain tiene integraciones mantenidas con OpenAI (GPT-4o, o3), Anthropic (Claude Sonnet, Claude Haiku), Google (Gemini), Meta (Llama 3), Mistral, Cohere y modelos locales desplegables vía Ollama o vLLM. La abstracción del LLM permite cambiar de proveedor sin reescribir la lógica de orquestación, lo que protege la inversión en desarrollo.
Se requiere un equipo con experiencia sólida en Python y en diseño de arquitecturas de software. LangChain no requiere conocimientos de machine learning ni entrenamiento de modelos. El principal reto técnico está en el diseño correcto de prompts, la gestión del estado de la conversación y la integración segura con sistemas existentes.
LangSmith, la plataforma de observabilidad oficial de LangChain, permite trazar cada llamada al modelo, medir latencias, contar tokens por componente, comparar versiones de prompts y detectar regresiones. En proyectos enterprise, se complementa con sistemas de monitorización existentes como Datadog, Prometheus o ELK mediante instrumentación estándar.
Sí. LangChain es agnóstico al despliegue. Puede operar completamente on-premise con modelos locales —Llama o Mistral vía Ollama/vLLM—, bases de datos locales y sin ninguna llamada a APIs externas. Esta capacidad es especialmente relevante para sectores con requisitos estrictos de soberanía de datos o privacidad de la información.
Un prototipo funcional con un agente básico —conversación, memoria de contexto y dos o tres herramientas integradas— puede estar listo en una o dos semanas de desarrollo. El tiempo hasta producción depende de la complejidad de las integraciones, los requisitos de seguridad y los procesos de validación internos. Hopla! ha desarrollado marcos de aceleración que reducen significativamente este tiempo para perfiles de caso de uso recurrentes en entornos enterprise.
Impulse la orquestación de IA en su empresa con Hopla!
Su empresa necesita avanzar en sistemas de IA basados en LangChain y LangGraph con un enfoque seguro, escalable y adaptado a sus objetivos.
Contacte con el equipo de Hopla! y analice el siguiente paso para su proyecto tecnológico.


