


La evolución necesaria para datos a escala, en tiempo real y con gobernanza.
La evolución del almacenamiento de datos
El auge de la era digital ha incrementado la necesidad de recopilar, almacenar y procesar grandes volúmenes de información. Esta realidad ha llevado a empresas y organizaciones a adoptar arquitecturas y estrategias de almacenamiento robustas, capaces de responder a las exigencias actuales de rapidez, flexibilidad y escalabilidad.
En las primeras etapas de esta evolución surgió el concepto de data warehouse, diseñado para consolidar y centralizar datos procedentes de diferentes fuentes. Estos datos debían ser previamente procesados y depurados mediante procesos ETL, siglas de Extract, Transform, Load.
Estos datos debían ser previamente procesados y depurados mediante procesos ETL, siglas de Extract, Transform, Load. Entre los casos de uso más comunes de los data warehouses destacan el análisis empresarial, la generación de informes estratégicos y la elaboración de métricas clave para orientar la toma de decisiones.
Asimismo, también cumplen un papel relevante en iniciativas de inteligencia artificial (IA), especialmente para la detección de patrones y tendencias.
Limitaciones del data warehouse en entornos real time
Sin embargo, los data warehouses presentan limitaciones en escenarios que requieren flexibilidad para almacenar datos semiestructurados o no estructurados. Al depender de un alto nivel de preprocesado, pueden aumentar los costes y reducir la velocidad de procesamiento. Ambos factores son críticos en entornos real time.
Estas limitaciones impulsaron la aparición de los data lakes.
A diferencia de los data warehouses, los data lakes permiten almacenar la información directamente en su formato original, ya se trate de datos estructurados, semiestructurados o no estructurados.Esta solución se consolidó especialmente en entornos de aprendizaje automático, donde la exploración de datos en crudo resulta fundamental para la generación de modelos predictivos.
El riesgo de convertir un data lake en un data swamp
No obstante, el uso de data lakes sin una estrategia adecuada de gobernanza y control de calidad puede provocar su degradación hacia un data swamp.
En estos casos, la falta de control puede generar resultados incorrectos y derivar en predicciones erróneas.
Por ello, las soluciones Lakehouse, que combinan la estructuración y la gobernanza del data warehouse con la flexibilidad del data lake, ofrecen una alternativa sólida para empresas y organizaciones que necesitan escalabilidad, flexibilidad y control sobre sus datos.
Este tipo de soluciones permite unificar los datos en una única plataforma, eliminando movimientos innecesarios y reduciendo la complejidad operativa.
Al mismo tiempo, facilita el análisis preciso de datos estructurados y mantiene la posibilidad de trabajar con la información en su formato original.
Además, las arquitecturas Lakehouse suelen integrar mecanismos de control de accesos, trazabilidad y versionado, lo que contribuye a garantizar una gestión responsable de los datos.
Watsonx.data: una arquitectura Lakehouse para escalar tu estrategia de datos
Motores open source y gobernados para una estrategia de datos más eficiente, flexible y preparada para IA.
Introducción: más allá del almacenamiento clásico
En nuestro post “Del Data Warehouse al Lakehouse”, analizamos cómo la creciente necesidad de flexibilidad y gobernanza impulsó la aparición de la arquitectura Lakehouse.
En este contexto, la inteligencia artificial (IA) ya no se plantea como una iniciativa aislada, sino como parte de una estrategia de datos bien definida.
Soluciones como IBM watsonx permiten orquestar el ciclo de vida completo de la inteligencia artificial mediante tres componentes clave:
- watsonx.ai: plataforma para la colaboración, el desarrollo y el despliegue de modelos de inteligencia artificial, incluyendo modelos clásicos y generativos.
- watsonx.data: Lakehouse que permite optimizar los costes de almacenamiento y procesamiento, manteniendo un acceso eficiente y escalable a los datos.
- watsonx.governance: solución para el gobierno de modelos de inteligencia artificial y cumplimiento normativo, que ayuda a asegurar la calidad y a evitar riesgos.
Este enfoque tiene como objetivo facilitar el almacenamiento, el acceso y la transformación de los datos de forma ágil y eficiente, adaptándose a las necesidades de cada caso de uso.
Watsonx.data: cómo romper con la fragmentación de la información
El gran valor diferencial de watsonx.data es que permite acabar con el aislamiento de los datos, ofreciendo acceso desde una misma plataforma a diferentes fuentes de información.
El siguiente diagrama representa los principales componentes de la arquitectura de watsonx.data.
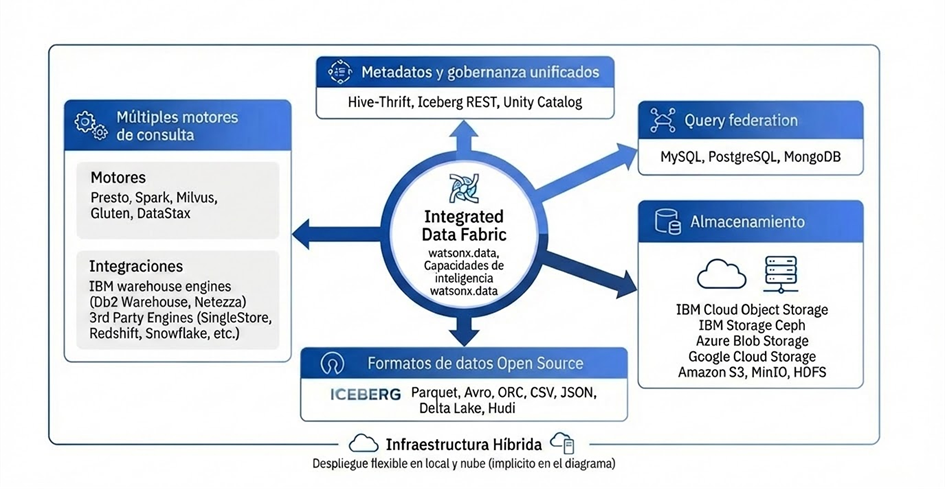
Componentes clave de watsonx.data
Integrated data fabric
Integrated data fabric es la capa que permite conectar y gestionar datos distribuidos en múltiples sistemas como si formaran parte de una única plataforma.
De esta forma, evita la duplicación de información y facilita su preparación para proyectos de IA.
Múltiples motores de consulta
Watsonx.data permite utilizar el motor más adecuado según el tipo de carga de trabajo.
Esto ayuda a optimizar tanto el rendimiento como el coste en función de cada caso de uso.
Entre los principales motores se encuentran:
- Presto: motor SQL de alto rendimiento diseñado para analítica interactiva a gran escala. Permite consultar datos en el Data Lake con la velocidad de un Warehouse, pero con una eficiencia de costes significativamente mayor.
- Spark: motor de referencia para el procesamiento de datos masivos. Es ideal para tareas de ingeniería de datos, ETL y pipelines necesarios para alimentar modelos de machine learning e IA.
- Gluten: mejora Apache Spark al permitir la ejecución de consultas utilizando el motor Velox y reduciendo la sobrecarga del entorno JVM.
- Milvus: motor de base de datos vectorial optimizado para IA generativa, que permite buscar y recuperar información no estructurada de forma eficiente.
- DataStax (Cassandra): motor NoSQL distribuido con capacidades vectoriales, diseñado para soportar cargas operativas y aplicaciones en tiempo real, especialmente en escenarios que requieren baja latencia y alta escalabilidad.
Además, watsonx.data se integra con motores externos como IBM watsonx.data Warehouse, Netezza, Db2 Warehouse, Redshift o Snowflake.
Gobernanza, metadatos y seguridad integrados
Watsonx.data incorpora una capa de gobernanza que permite gestionar el acceso, la calidad y el cumplimiento normativo de los datos de forma centralizada.
Este punto es clave para garantizar la confianza en los datos y en los modelos de IA que se construyen sobre ellos.
Formato de datos open source
La solución se basa en formatos de tabla abiertos, como Apache Iceberg, Parquet u ORC.
Esto permite que diferentes motores puedan leer y escribir sobre los mismos datos simultáneamente, sin necesidad de duplicar la información.
Además, estos formatos aportan capacidades avanzadas como transacciones ACID, evolución de esquemas y versionado de datos.
Query federation
Uno de los pilares de watsonx.data es la capacidad de consultar datos directamente desde múltiples sistemas, como bases de datos, data warehouses u object storage, sin necesidad de moverlos.
Esto reduce la duplicación de datos, simplifica la arquitectura y permite construir una capa lógica unificada de acceso a la información.
Almacenamiento desacoplado del cómputo
El almacenamiento de watsonx.data está completamente desacoplado del cómputo y soporta múltiples sistemas, como IBM Cloud Object Storage, Ceph, Amazon S3, Azure Blob, Google Cloud Storage, MinIO o HDFS.
Este enfoque permite escalar de forma independiente y optimizar costes mediante el uso de almacenamiento masivo y económico.
Infraestructura híbrida y abierta
Watsonx.data está diseñado para desplegarse en entornos cloud, on-premise o multicloud, adaptándose a los requisitos de cada organización.
Este enfoque facilita la integración con herramientas de terceros, bases de datos existentes y ecosistemas analíticos ya desplegados.
Watsonx.data y arquitectura Lakehouse: eficiencia para datos e IA
En resumen, con watsonx.data es posible elegir el motor más eficiente para cada tarea y separar el cómputo del almacenamiento.
Esto permite reducir los costes de almacenamiento y computación en comparación con los Data Warehouses tradicionales.
Gracias a una arquitectura Lakehouse abierta, gobernada y escalable, las organizaciones pueden avanzar hacia una estrategia de datos más flexible, preparada para IA y alineada con las necesidades reales de cada caso de uso.
Para avanzar hacia una arquitectura Lakehouse más flexible, gobernada y preparada para IA en Hopla te ayudamos a diseñar, integrar y optimizar una estrategia de datos adaptada a las necesidades de tu organización.
Contacte con nuestro equipo y descubra cómo podemos ayudarle a sacar más valor de sus datos.


